

Объединить повторяющиеся значения в excel
Слияние двух списков без дубликатов
Классическая ситуация: у вас есть два списка, которые надо слить в один. Причем в исходных списках могут быть как уникальные элементы, так и совпадающие (и между списками и внутри), но на выходе нужно получить список без дубликатов (повторений):

Давайте традиционно рассмотрим несколько способов решения такой распространенной задачи — от примитивных «в лоб» до более сложных, но изящных.
Способ 1. Удаление дубликатов
Можно решить задачу самым простым путем — руками скопировать элементы обоих списков в один и применить потом к полученному набору инструмент Удалить дубликаты с вкладки Данные (Data — Remove Duplicates) :
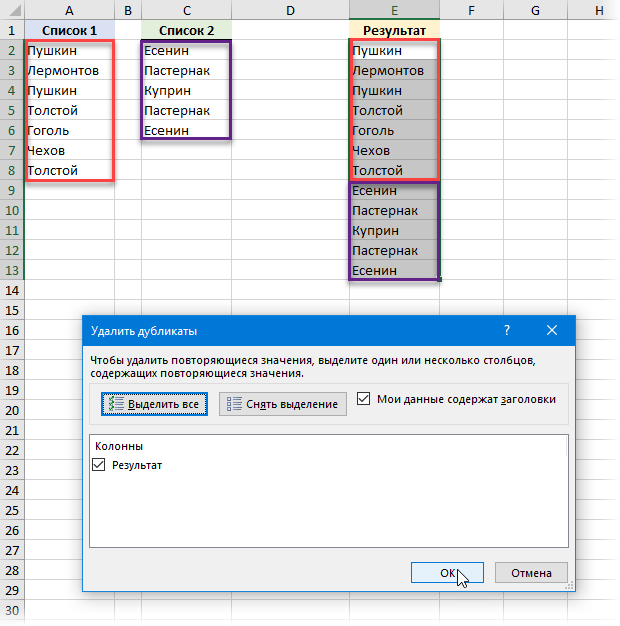
Само-собой, такой способ не подойдет, если данные в исходных списках часто меняются — придется повторять всю процедуру после каждого изменения заново.
Способ 1а. Сводная таблица
Этот способ является, по сути, логическим продолжением предыдущего. Если списки не очень большого размера и заранее известно предельное количество элементов в них (например, не больше 10), то можно объединить две таблицы в одну прямыми ссылками, добавить справа столбец с единичками и построить по получившейся таблице сводную:
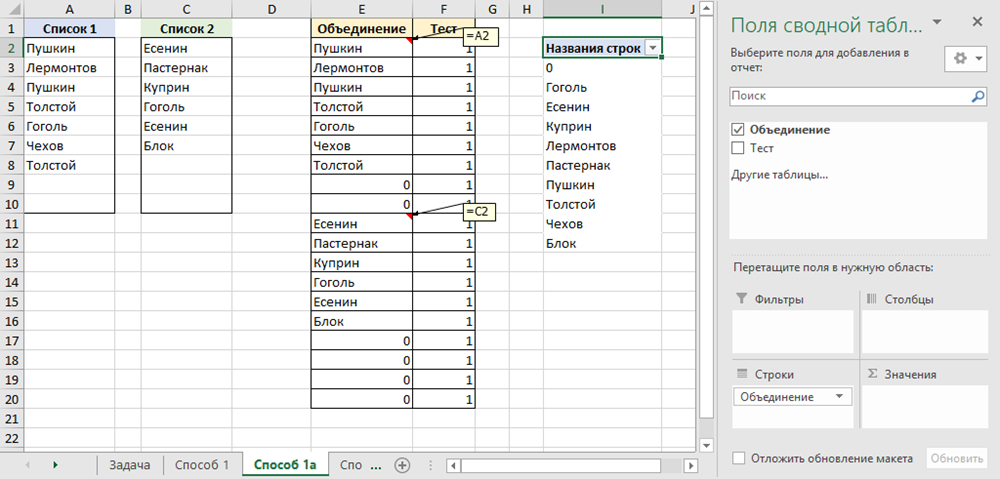
Как известно, сводная таблица игнорирует повторы, поэтому на выходе мы получим объединенный список без дубликатов. Вспомогательный столбец с 1 нужен только потому, что Excel умеет строить сводные по таблицам, содержащим, по крайней мере, два столбца.
При изменении исходных списков новые данные по прямым ссылкам попадут в объединенную таблицу, но сводную придется обновить уже вручную (правой кнопкой мыши — Обновить). Если не нужен пересчет «на лету», то лучше воспользоваться другими вариантами.
Способ 2. Формула массива
Можно решить проблему формулами. В этом случае пересчет и обновление результатов будет происходить автоматически и мгновенно, сразу после изменений в исходных списках. Для удобства и краткости давайте дадим нашим спискам имена Список1 и Список2, используя Диспетчер имен на вкладке Формулы (Formulas — Name Manager — Create) :
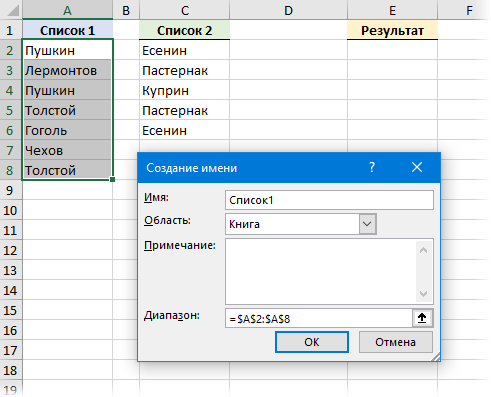
После именования, нужная нам формула будет выглядеть следующим образом:
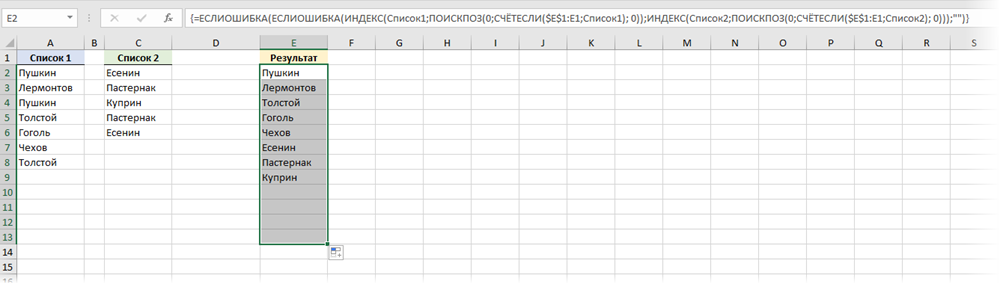
На первый взгляд выглядит жутковато, но, на самом деле, все не так страшно. Давайте я разложу эту формулу на несколько строк, используя сочетание клавиш Alt+Enter и отступы пробелами, как мы делали, например тут:
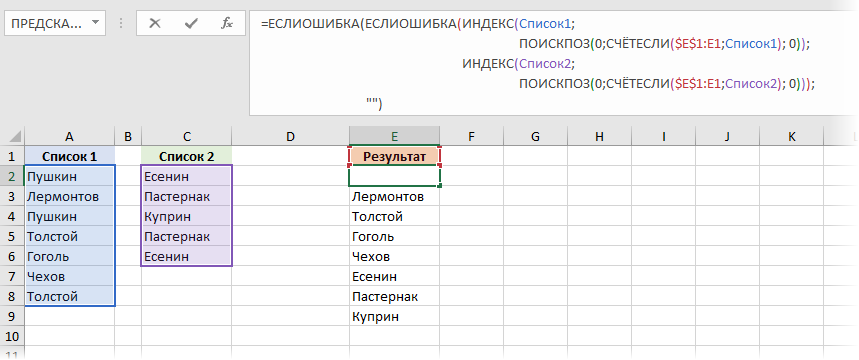
Логика тут следующая:
- Формула ИНДЕКС(Список1;ПОИСКПОЗ(0;СЧЁТЕСЛИ($E$1:E1;Список1); 0) выбирает все уникальные элементы из первого списка. Как только они заканчиваются — начинает выдавать ошибку #Н/Д:
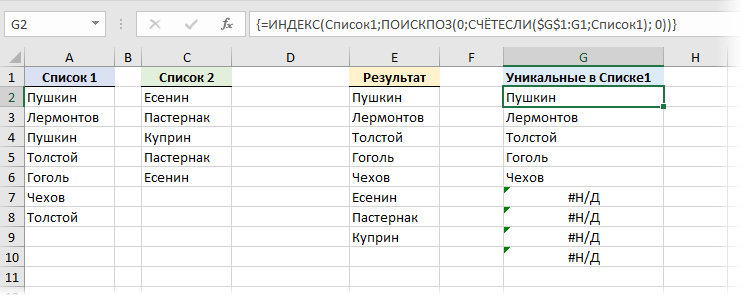
Обратите внимание, что это формула массива, т.е. после набора ее нужно ввести в ячейку не обычным Enter , а сочетанием клавиш Ctrl + Shift + Enter и затем скопировать (протянуть) вниз на нижестоящие ячейки с запасом.
В английской версии Excel эта формула выглядит как:
=IFERROR(IFERROR(INDEX(Список1, MATCH(0, COUNTIF($E$1:E1, Список1), 0)), INDEX(Список2, MATCH(0, COUNTIF($E$1:E1, Список2), 0))), «»)
Минус у такого подхода в том, что формулы массива ощутимо замедляют работу с файлом, если в исходных таблицах большое (несколько сотен и более) количество элементов.
Способ 3. Power Query
Если в ваших исходных списках большое количество элементов, например, по несколько сотен или тысяч, то вместо медленной формулы массива лучше использовать принципиально другой подход, а именно — инструменты надстройки Power Query. Эта надстройка по умолчанию встроена в Excel 2016. Если у вас Excel 2010 или 2013, то ее можно отдельно скачать и установить (бесплатно).
Алгоритм действий следующий:
- Открываем отдельную вкладку установленной надстройки Power Query (если у вас Excel 2010-2013) или просто идем на вкладку Данные (если у вас Excel 2016).
- Выделяем первый список и жмем кнопку Из таблицы/диапазона (From Range/Table) . На вопрос про создание из нашего списка «умной таблицы» — соглашаемся:
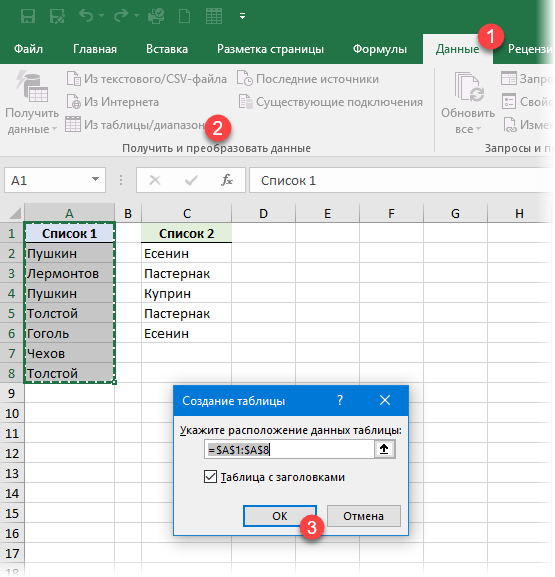
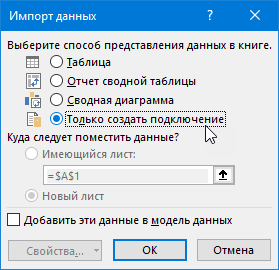
В следующем диалоговом окне (оно может выглядеть немного по-другому — не пугайтесь) выбираем Только создать подключение (Only create connection) :
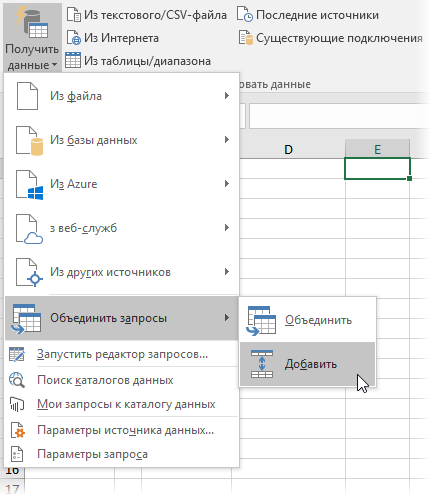
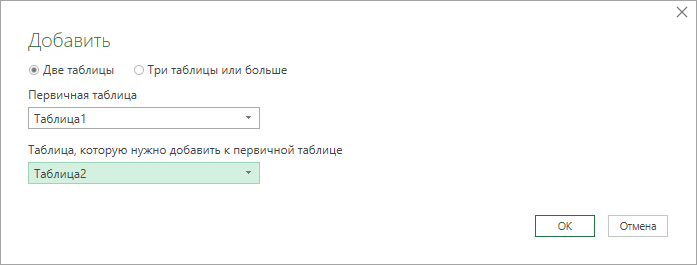
В появившемся диалоговом окне выбираем наши запросы из выпадающих списков:
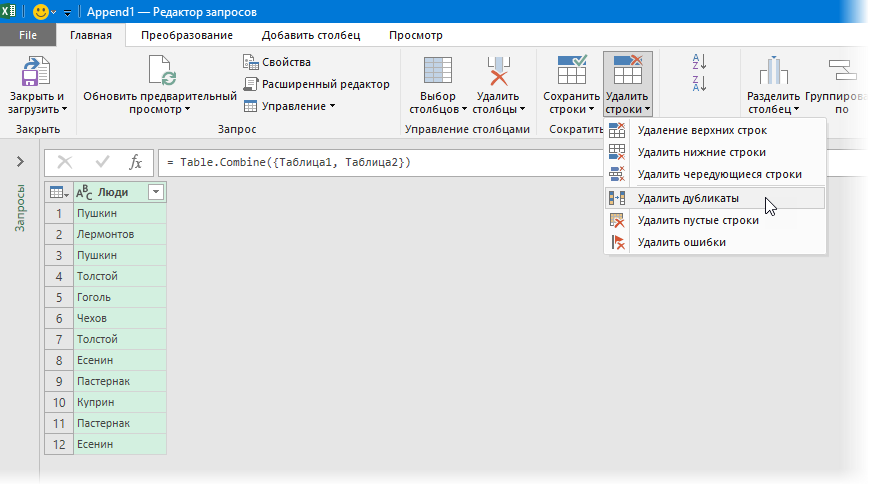
В итоге получим новый запрос, где два списка будут соединены друг под другом. Осталось удалить дубликаты кнопкой Удалить строки — Удалить дубликаты (Delete Rows — Delete Duplicates) :
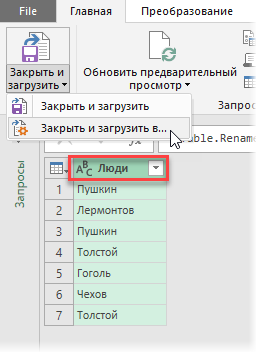
Готовый запрос можно переименовать справа на панели параметров, дав ему вменяемое имя (это будет имя таблицы-результата по факту) и все и можно все выгружать на лист командой Закрыть и загрузить (Close&Load) :
В будущем, при любых изменениях или дополнениях в исходных списках, достаточно будет лишь правой кнопкой мыши обновить таблицу результатов.
Exceltip
Блог о программе Microsoft Excel: приемы, хитрости, секреты, трюки
Повторяющиеся значения в Excel — найти, выделить или удалить дубликаты в Excel

В сегодняшних Excel файлах дубликаты встречаются повсеместно. К примеру, когда вы создаете составную таблицу из других таблиц, вы можете обнаружить в ней повторяющиеся значения, или в файле с общим доступом внесли одинаковые данные два разных пользователя, что привело к задвоению и т.д. Дубликаты могут возникнуть в одном столбце, в нескольких столбцах или даже во всем листе. В Microsoft Excel реализовано несколько инструментов поиска, выделения и, при необходимости, удаления повторяющихся значений. Ниже описаны основные методики определения дубликатов в Excel.
1. Удаление повторяющихся значений в Excel (2007+)
Предположим, у вас имеется таблица, состоящая из трех столбцов, в которой присутствуют одинаковые записи и вам необходимо избавится от них. Выделяем область таблицы, в которой хотите удалить повторяющиеся значения. Вы можете выделить один или несколько столбцов, или всю таблицу целиком. Переходим по вкладке Данные в группу Работа с данными, щелкаем по кнопке Удалить дубликаты.
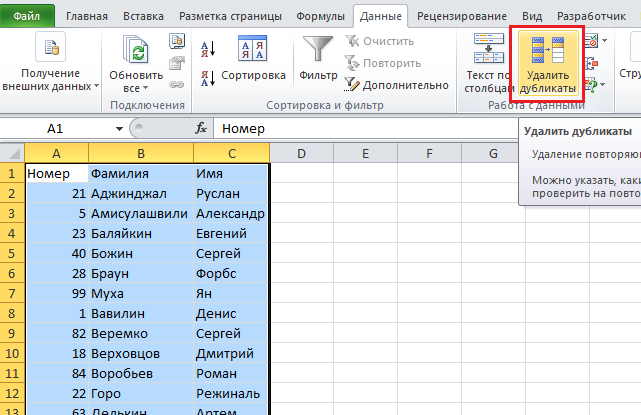
Если в каждом столбце таблицы имеется заголовок, установить маркер Мои данные содержат заголовки. Также проставляем маркеры напротив тех столбцов, в которых требуется произвести поиск дубликатов.
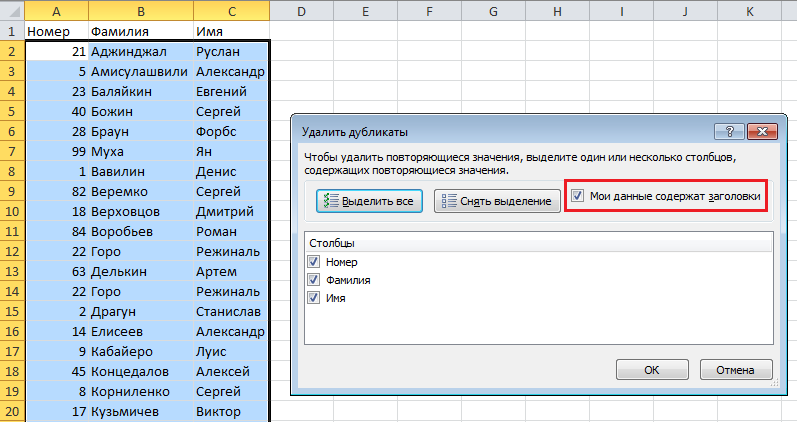
Щелкаем ОК, диалоговое окно будет закрыто и строки, содержащие дубликаты будут удалены.
Данная функция предназначена для удаления записей, которые полностью дублируют строки в таблице. Если вы выделили не все столбцы для определения дубликатов, строки с повторяющимися значениями также будут удалены.
2. Использование расширенного фильтра для удаления дубликатов
Выберите любую ячейку в таблице, перейдите по вкладке Данные в группу Сортировка и фильтр, щелкните по кнопке Дополнительно.
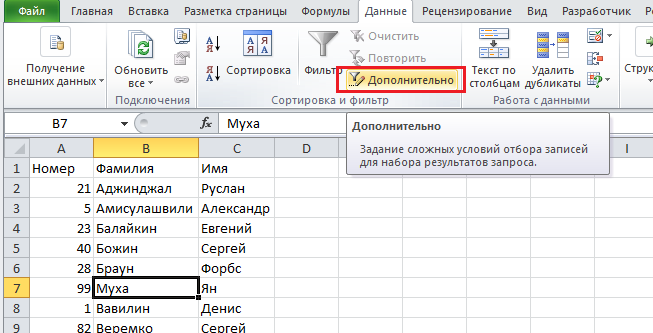
В появившемся диалоговом окне Расширенный фильтр, необходимо установить переключатель в положение скопировать результат в другое место, в поле Исходный диапазон указать диапазон, в котором находится таблица, в поле Поместить результат в диапазон указать верхнюю левую ячейку будущей отфильтрованной таблицы и установить маркер Только уникальные значения. Щелкаем ОК.
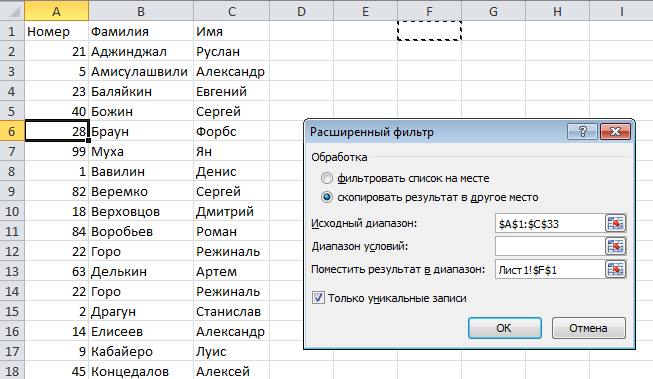
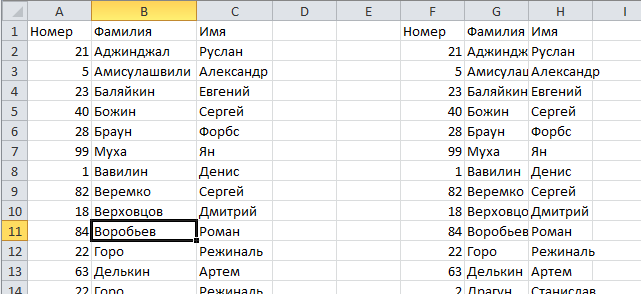
На месте, указанном для размещения результатов работы расширенного фильтра, будет создана еще одна таблица, но уже с отфильтрованными, по уникальным значениям, данными.
3. Выделение повторяющихся значений с помощью условного форматирования в Excel (2007+)
Выделяем таблицу, в которой необходимо обнаружить повторяющиеся значения. Переходим по вкладке Главная в группу Стили, выбираем Условное форматирование -> Правила выделения ячеек -> Повторяющиеся значения.
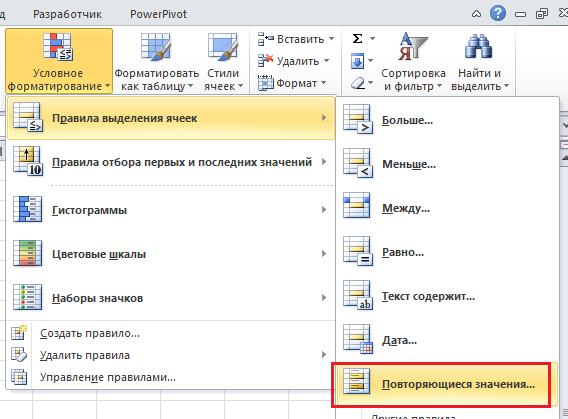
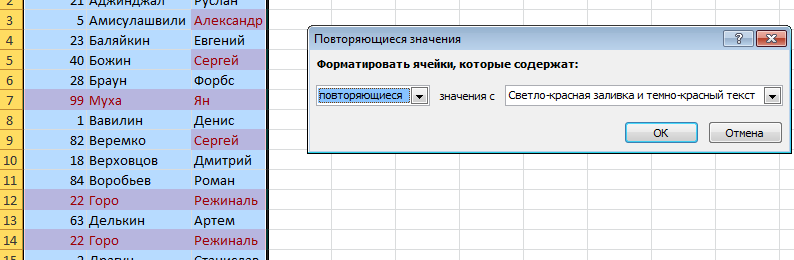
В появившемся диалоговом окне Повторяющиеся значения, необходимо выбрать формат выделения дубликатов. У меня по умолчанию установлено светло-красная заливка и темно-красный цвет текста. Обратите внимание, в данном случае Excel будет сравнивать на уникальность не всю строку таблицы, а лишь ячейку столбца, поэтому если у вас имеются повторяющиеся значения только в одном столбце, Excel отформатирует их тоже. На примере вы можете увидеть, как Excel залил некоторые ячейки третьего столбца с именами, хотя вся строка данной ячейки таблицы уникальна.
4. Использование сводных таблиц для определения повторяющихся значений
Воспользуемся уже знакомой нам таблицей с тремя столбцами и добавим четвертый, под названием Счетчик, и заполним его единицами (1). Выделяем всю таблицу и переходим по вкладке Вставка в группу Таблицы, щелкаем по кнопке Сводная таблица.
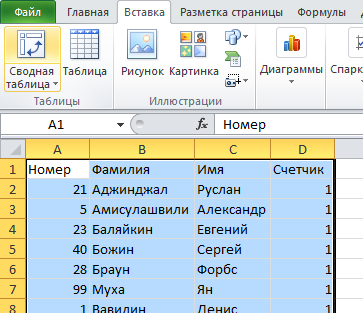
Создаем сводную таблицу. В поле Название строк помещаем три первых столбца, в поле Значения помещаем столбец со счетчиком. В созданной сводной таблице, записи со значением больше единицы будут дубликатами, само значение будет означать количество повторяющихся значений. Для большей наглядности, можно отсортировать таблицу по столбцу Счетчик, чтобы сгруппировать дубликаты.
Как объединить ячейки с одинаковым значением в Excel
В приходных накладных или прайсах очень часто повторяются некоторые значения ячеек в разных позициях. Если отсортировать эти значения не всегда удобно их визуально анализировать. Например, названия поставщиков могут быть очень похожими и какие данные к ним относятся легко спутать.
Как выделить одинаковые ячейки группами
Допустим мы имеем список поставщиков:
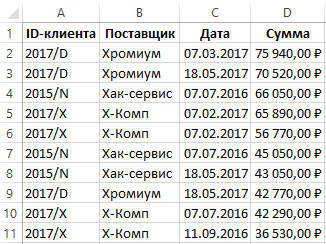
Перед тем как найти повторяющиеся ячейки в Excel, отсортируем поставщиков по их идентификатору. Переходим в ячейку A2 и выбираем на закладке «ДАННЫЕ» в разделе «Сортировка и фильтр» инструмент «Сортировка от А до Я».
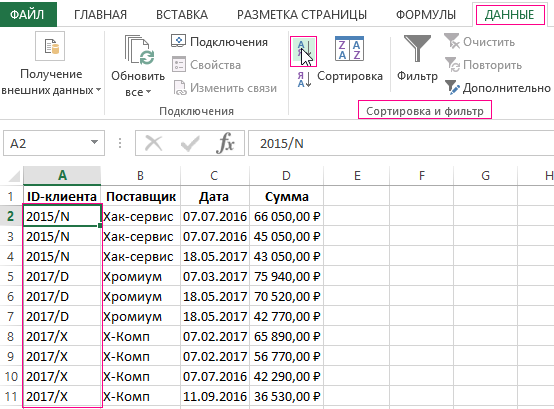
Чтобы автоматически отметить повторяющиеся ячейки и разделить их линиями на группы воспользуемся условным форматированием:
- Выделите диапазон A2:A11 и выберите инструмент: «ГЛАВНАЯ»-«Условное форматирование»-«Создать правило»-«Использовать формулу для определения форматированных ячеек:».
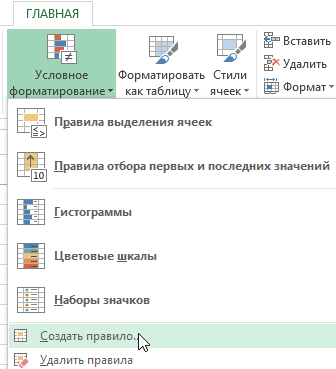

- В поле для ввода формулы вводим следующе значение: =$A2<>$A3
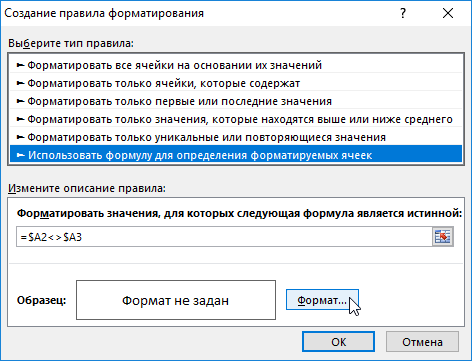
- Щелкните на кнопку «Формат», на вкладке «Граница» следует задать оформление для нижних границ строк. И ОК.
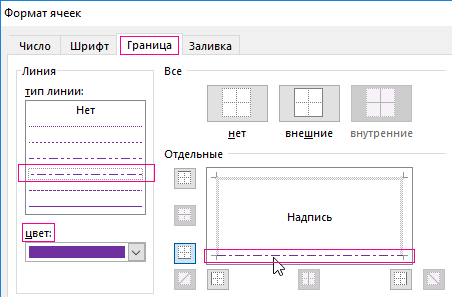
В результате получаем эффект как отображено на рисунке.
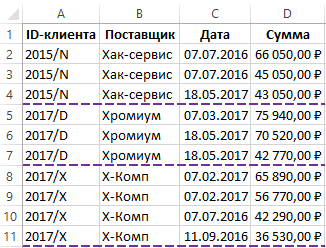
Нам удалось объединить и выделить повторяющиеся ячейки в Excel. Теперь в приходной накладной все отсортированные поставщики визуально разграничены линией друг от друга.
Так как мы сортировали поставщиков по их идентификатору в формуле мы зафиксировали смешанной ссылкой столбец листа $A. Если значения в соседних ячейках столбца $A равные между собой тогда формула возвращает значения ЛОЖЬ и форматирование границе не применяется. Но если верхнее значение неравно (оператор <>) нижнему значению тогда формула возвращает значение ИСТИНА и применяется форматирования нижней границы целой строки (так как в смешанной ссылке номер строки не есть абсолютным, а является относительным адресом).
Полезный совет! Если нужно разграничить данные не по первому столбцу таблицы, по любому другому, тогда соответственно отсортируйте и просто укажите адрес столбца. Например, разграничим по повторяющимся датам, а не по поставщикам. Для этого сначала сортируем данные по датам, а потом используем условное форматирование немного изменив формулу: =$C2<>$C3
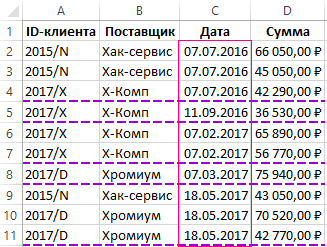
Теперь список сгруппирован по одинаковым датам.
Как в Excel найти повторяющиеся и одинаковые значения
При совместной работе с таблицами Excel или большом числе записей накапливаются дубли строк. Ста.
При совместной работе с таблицами Excel или большом числе записей накапливаются дубли строк. Статья посвящена тому, как выделить повторяющиеся значения в Excel, удалить лишние записи или сгруппировать, получив максимум информации.

Поиск одинаковых значений в Excel
Выберем одну из ячеек в таблице. Рассмотрим, как в Экселе найти повторяющиеся значения, равные содержимому ячейки, и выделить их цветом.
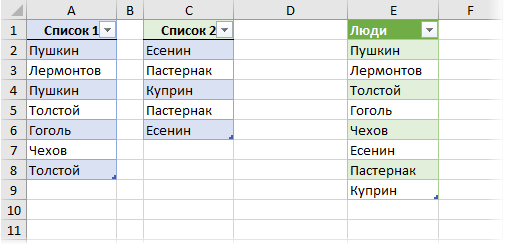
На рисунке – списки писателей. Алгоритм действий следующий:
- Выбрать ячейку I3 с записью «С. А. Есенин».
- Поставить задачу – выделить цветом ячейки с такими же записями.
- Выделить область поисков.
- Нажать вкладку «Главная».
- Далее группа «Стили».
- Затем «Условное форматирование»;
- Нажать команду «Равно».
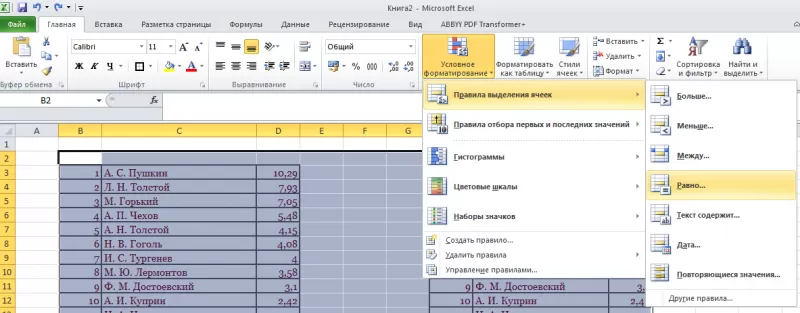
- Появится диалоговое окно:
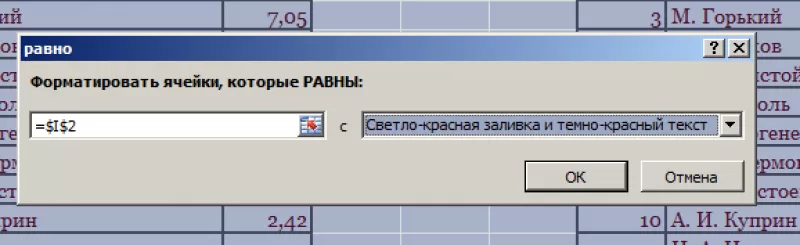
- В левом поле указать ячейку с I2, в которой записано «С. А. Есенин».
- В правом поле можно выбрать цвет шрифта.
- Нажать «ОК».
В таблицах отмечены цветом ячейки, значение которых равно заданному.
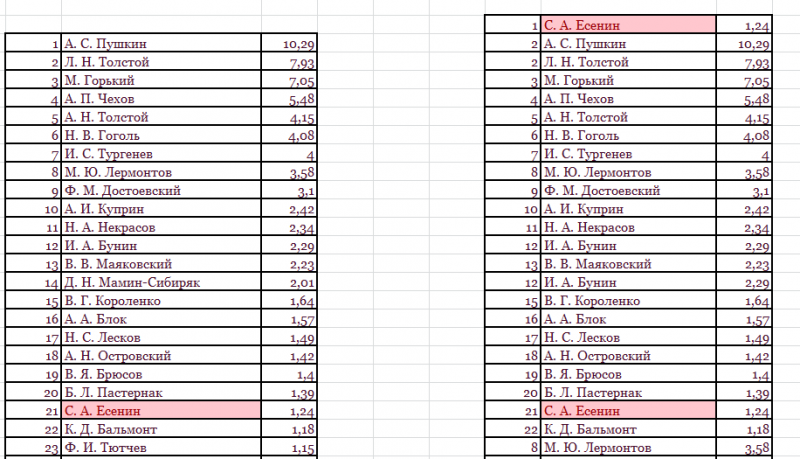
Несложно понять, как в Экселе найти одинаковые значения в столбце. Просто выделить перед поиском нужную область – конкретный столбец.
Ищем в таблицах Excel все повторяющиеся значения
Отметим все неуникальные записи в выделенной области. Для этого нужно:
- Зайти в группу «Стили».
- Далее «Условное форматирование».
- Теперь в выпадающем меню выбрать «Правила выделения ячеек».
- Затем «Повторяющиеся значения».
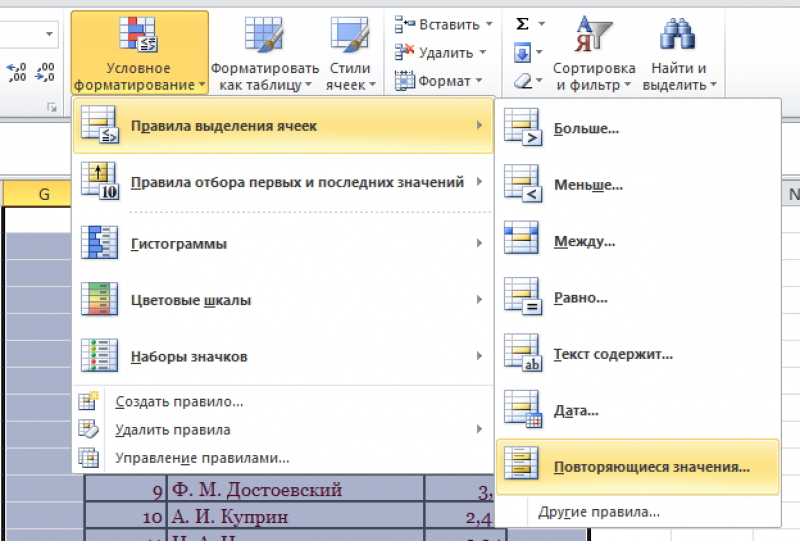
- Появится диалоговое окно:
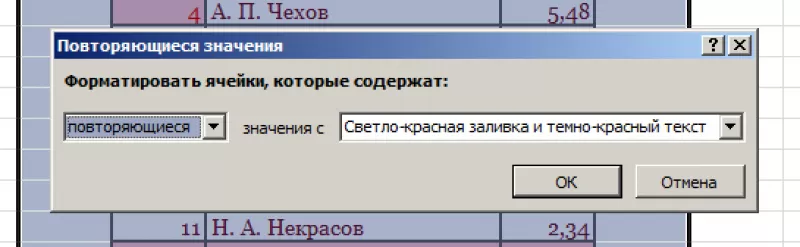
- Нажать «ОК».
Программа ищет повторения во всех столбцах.
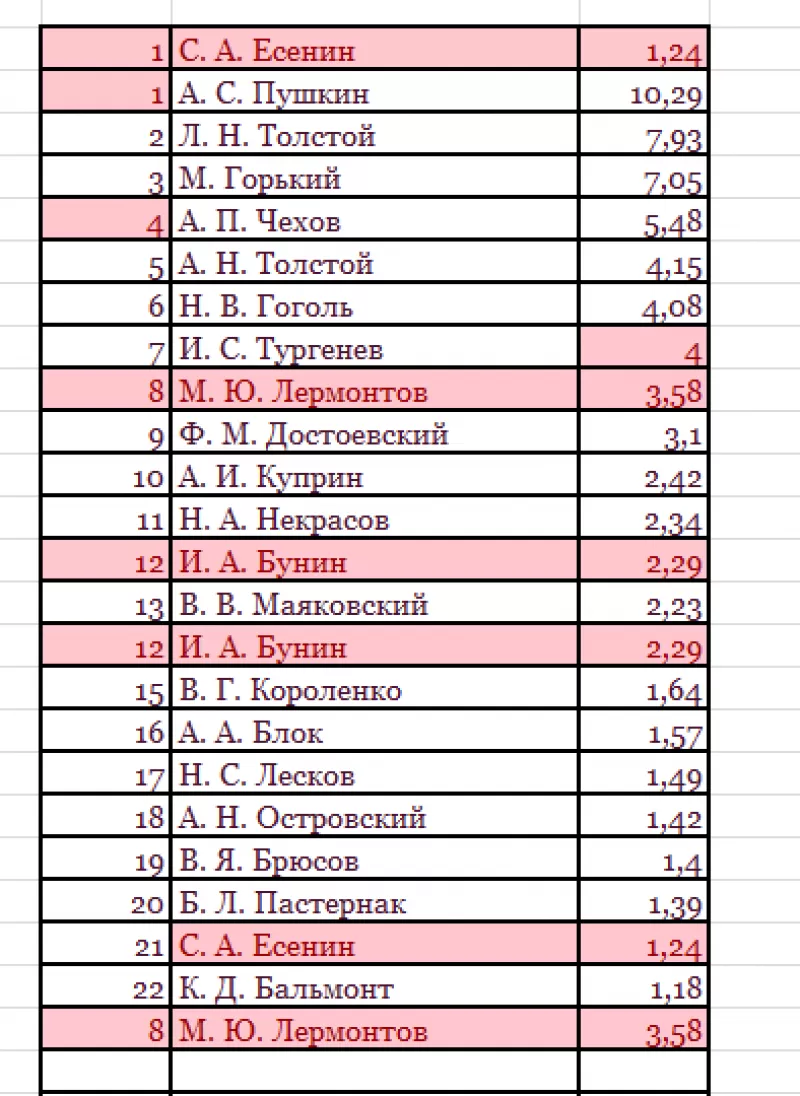
Если в таблице много неуникальных записей, то информативность такого поиска сомнительна.
Удаление одинаковых значений из таблицы Excel
Способ удаления неуникальных записей:
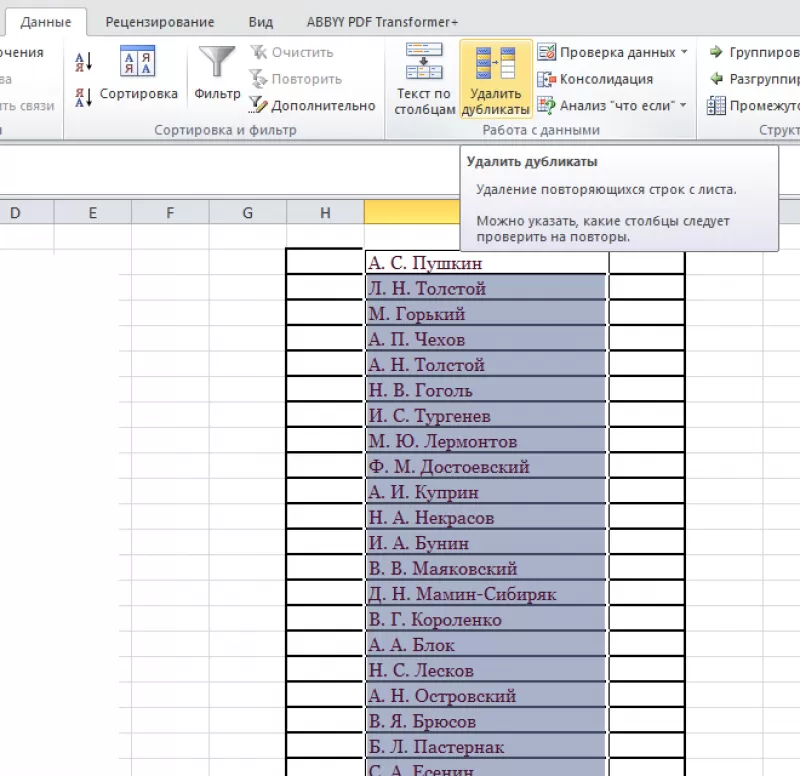
- Зайти во вкладку «Данные».
- Выделить столбец, в котором следует искать дублирующиеся строки.
- Опция «Удалить дубликаты».
В результате получаем список, в котором каждое имя фигурирует только один раз.
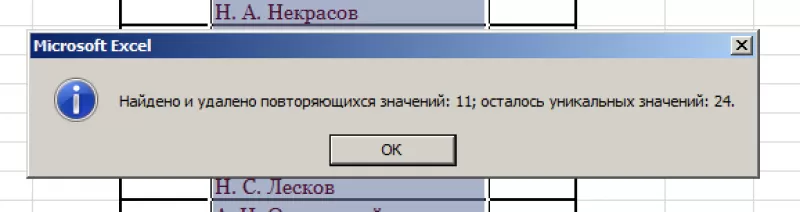
Список с уникальными значениями:

Расширенный фильтр: оставляем только уникальные записи
Расширенный фильтр – это инструмент для получения упорядоченного списка с уникальными записями.
- Выбрать вкладку «Данные».
- Перейти в раздел «Сортировка и фильтр».
- Нажать команду «Дополнительно»:
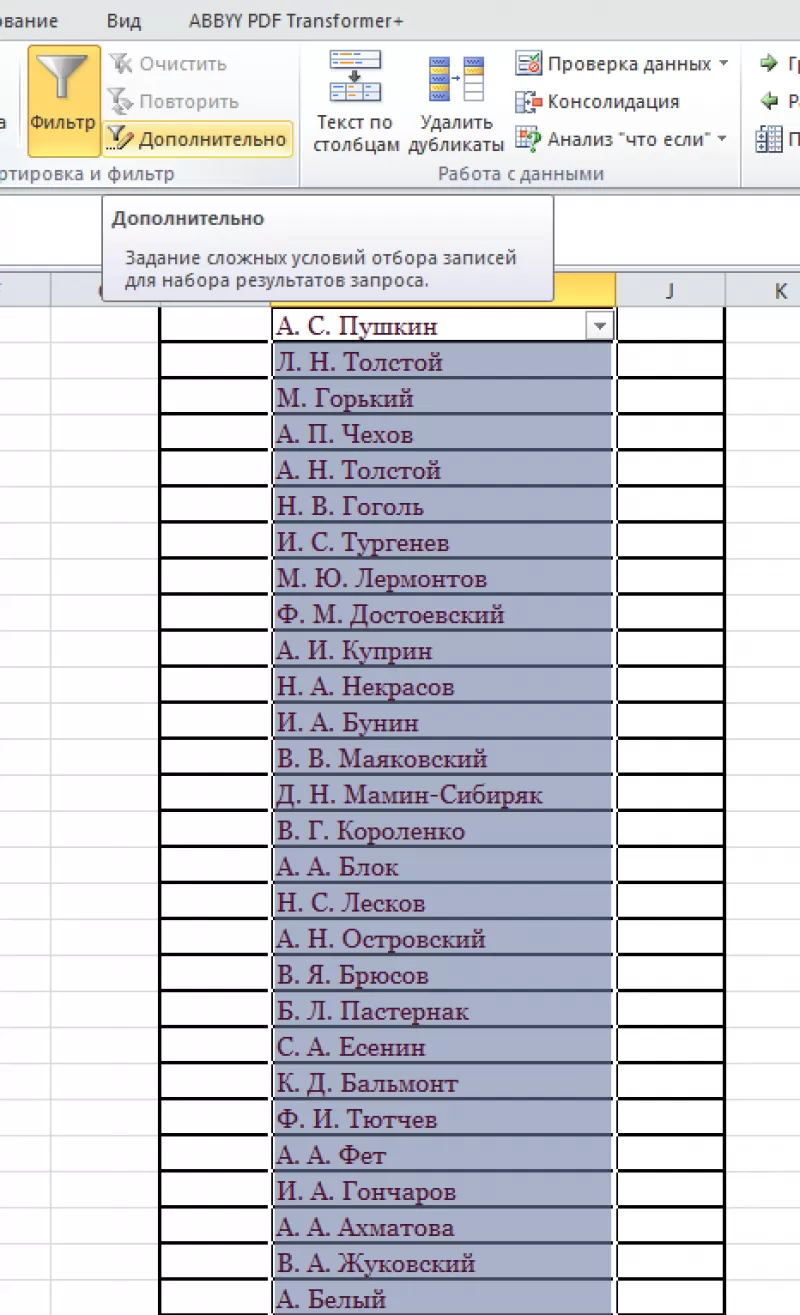
- В появившемся диалоговом окне ставим флажок «Только уникальные записи».
- Нажать «OK» – уникальный список готов.
Поиск дублирующихся значений с помощью сводных таблиц
Составим список уникальных строк, не теряя данные из других столбцов и не меняя исходную таблицу. Для этого используем инструмент Сводная таблица:
Пункт «Сводная таблица».
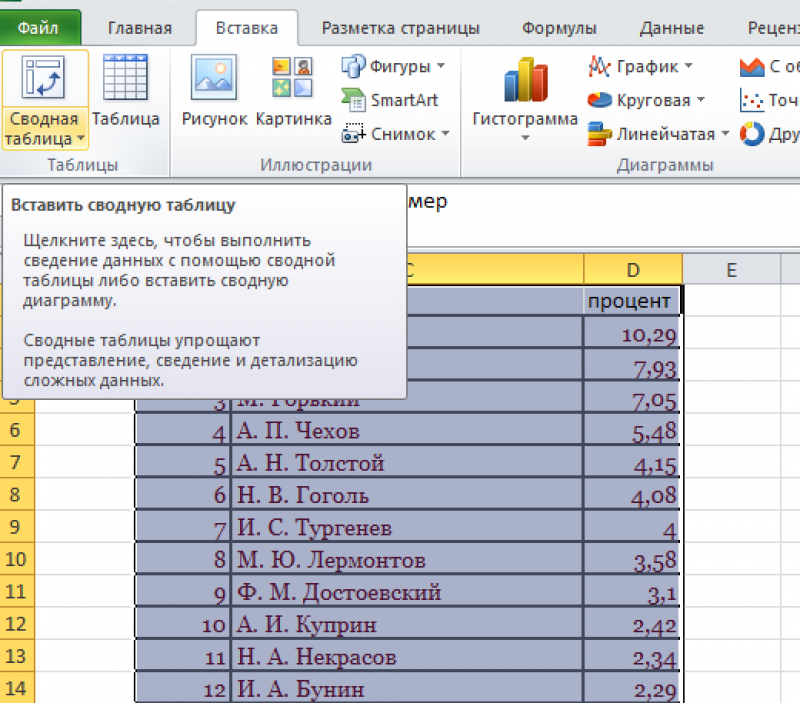
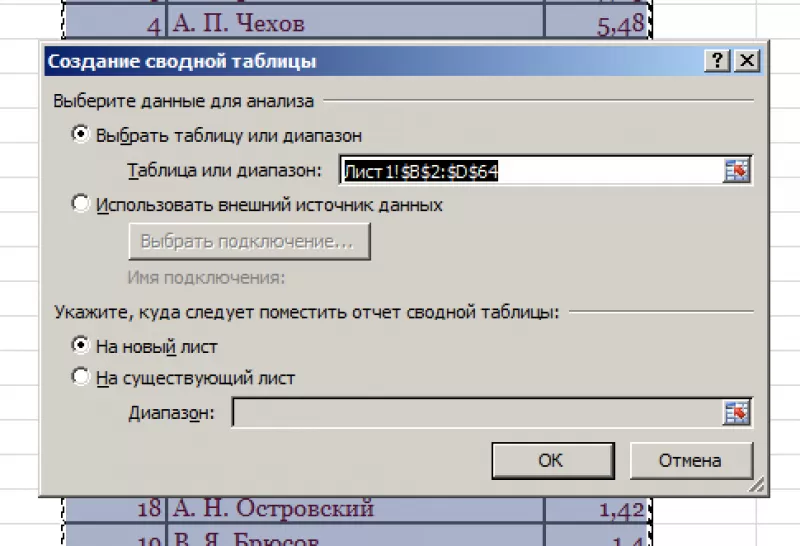
В диалоговом окне выбрать размещение сводной таблицы на новом листе.
В открывшемся окне отмечаем столбец, в котором содержатся интересующие нас значений.
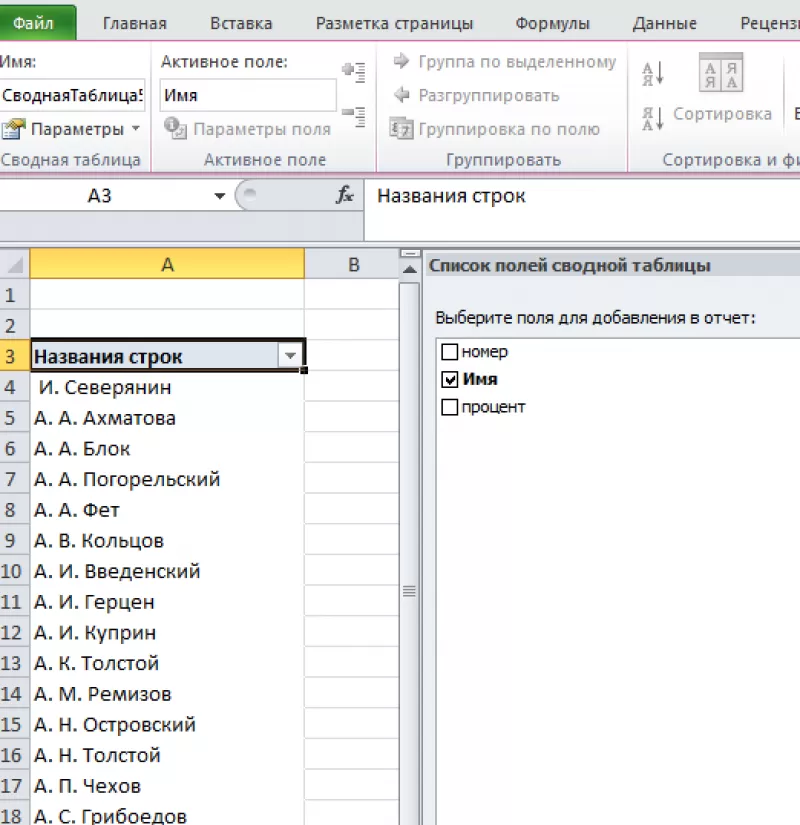
Получаем упорядоченный список уникальных строк.

