

Выделить одинаковые значения в столбцах excel
Exceltip
Блог о программе Microsoft Excel: приемы, хитрости, секреты, трюки
Повторяющиеся значения в Excel — найти, выделить или удалить дубликаты в Excel

В сегодняшних Excel файлах дубликаты встречаются повсеместно. К примеру, когда вы создаете составную таблицу из других таблиц, вы можете обнаружить в ней повторяющиеся значения, или в файле с общим доступом внесли одинаковые данные два разных пользователя, что привело к задвоению и т.д. Дубликаты могут возникнуть в одном столбце, в нескольких столбцах или даже во всем листе. В Microsoft Excel реализовано несколько инструментов поиска, выделения и, при необходимости, удаления повторяющихся значений. Ниже описаны основные методики определения дубликатов в Excel.
1. Удаление повторяющихся значений в Excel (2007+)
Предположим, у вас имеется таблица, состоящая из трех столбцов, в которой присутствуют одинаковые записи и вам необходимо избавится от них. Выделяем область таблицы, в которой хотите удалить повторяющиеся значения. Вы можете выделить один или несколько столбцов, или всю таблицу целиком. Переходим по вкладке Данные в группу Работа с данными, щелкаем по кнопке Удалить дубликаты.
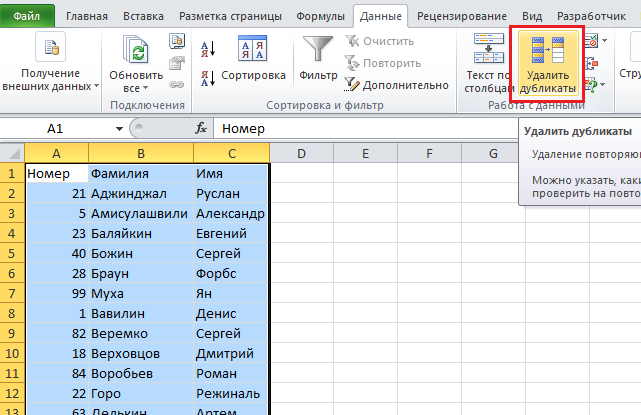
Если в каждом столбце таблицы имеется заголовок, установить маркер Мои данные содержат заголовки. Также проставляем маркеры напротив тех столбцов, в которых требуется произвести поиск дубликатов.
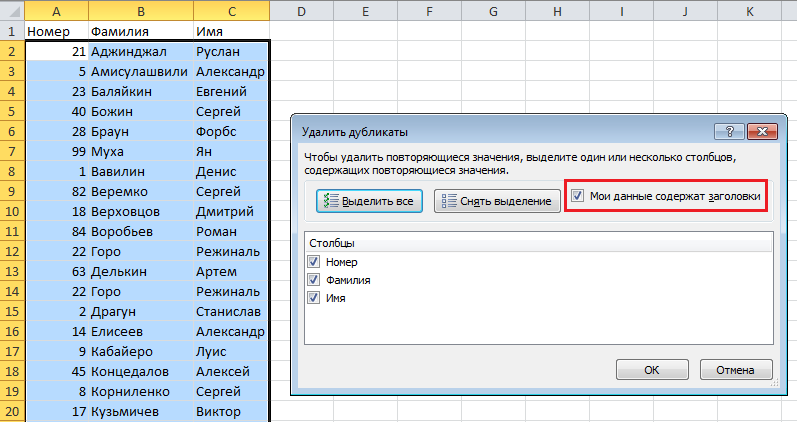
Щелкаем ОК, диалоговое окно будет закрыто и строки, содержащие дубликаты будут удалены.
Данная функция предназначена для удаления записей, которые полностью дублируют строки в таблице. Если вы выделили не все столбцы для определения дубликатов, строки с повторяющимися значениями также будут удалены.
2. Использование расширенного фильтра для удаления дубликатов
Выберите любую ячейку в таблице, перейдите по вкладке Данные в группу Сортировка и фильтр, щелкните по кнопке Дополнительно.
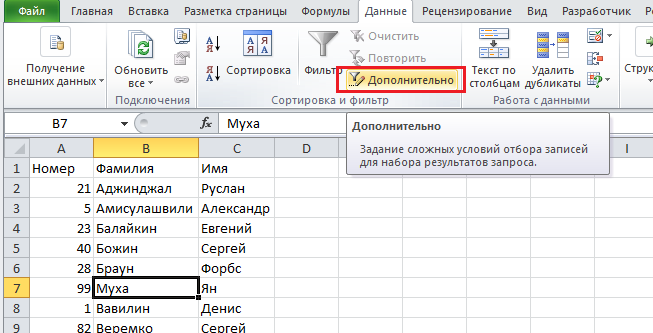
В появившемся диалоговом окне Расширенный фильтр, необходимо установить переключатель в положение скопировать результат в другое место, в поле Исходный диапазон указать диапазон, в котором находится таблица, в поле Поместить результат в диапазон указать верхнюю левую ячейку будущей отфильтрованной таблицы и установить маркер Только уникальные значения. Щелкаем ОК.
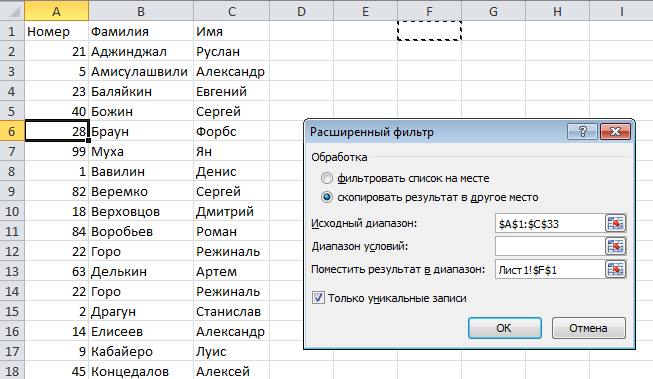
На месте, указанном для размещения результатов работы расширенного фильтра, будет создана еще одна таблица, но уже с отфильтрованными, по уникальным значениям, данными.
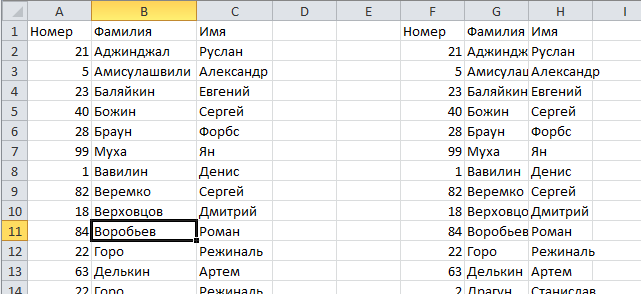
3. Выделение повторяющихся значений с помощью условного форматирования в Excel (2007+)
Выделяем таблицу, в которой необходимо обнаружить повторяющиеся значения. Переходим по вкладке Главная в группу Стили, выбираем Условное форматирование -> Правила выделения ячеек -> Повторяющиеся значения.
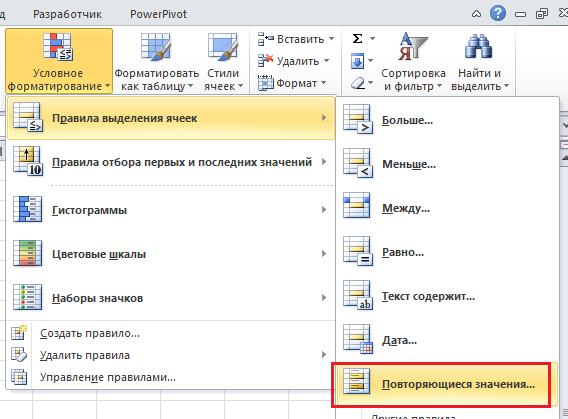
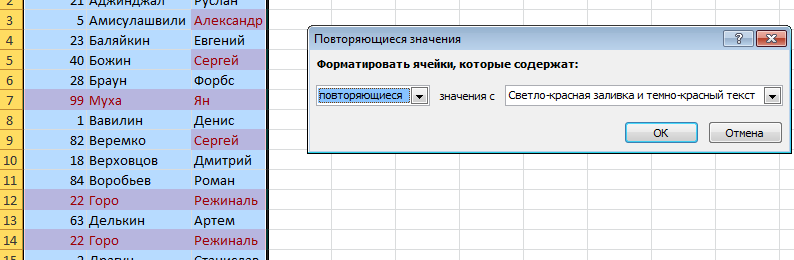
В появившемся диалоговом окне Повторяющиеся значения, необходимо выбрать формат выделения дубликатов. У меня по умолчанию установлено светло-красная заливка и темно-красный цвет текста. Обратите внимание, в данном случае Excel будет сравнивать на уникальность не всю строку таблицы, а лишь ячейку столбца, поэтому если у вас имеются повторяющиеся значения только в одном столбце, Excel отформатирует их тоже. На примере вы можете увидеть, как Excel залил некоторые ячейки третьего столбца с именами, хотя вся строка данной ячейки таблицы уникальна.
4. Использование сводных таблиц для определения повторяющихся значений
Воспользуемся уже знакомой нам таблицей с тремя столбцами и добавим четвертый, под названием Счетчик, и заполним его единицами (1). Выделяем всю таблицу и переходим по вкладке Вставка в группу Таблицы, щелкаем по кнопке Сводная таблица.
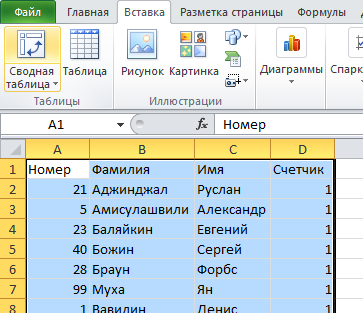
Создаем сводную таблицу. В поле Название строк помещаем три первых столбца, в поле Значения помещаем столбец со счетчиком. В созданной сводной таблице, записи со значением больше единицы будут дубликатами, само значение будет означать количество повторяющихся значений. Для большей наглядности, можно отсортировать таблицу по столбцу Счетчик, чтобы сгруппировать дубликаты.
Как в Excel найти повторяющиеся и одинаковые значения
При совместной работе с таблицами Excel или большом числе записей накапливаются дубли строк. Ста.
При совместной работе с таблицами Excel или большом числе записей накапливаются дубли строк. Статья посвящена тому, как выделить повторяющиеся значения в Excel, удалить лишние записи или сгруппировать, получив максимум информации.

Поиск одинаковых значений в Excel
Выберем одну из ячеек в таблице. Рассмотрим, как в Экселе найти повторяющиеся значения, равные содержимому ячейки, и выделить их цветом.
На рисунке – списки писателей. Алгоритм действий следующий:
- Выбрать ячейку I3 с записью «С. А. Есенин».
- Поставить задачу – выделить цветом ячейки с такими же записями.
- Выделить область поисков.
- Нажать вкладку «Главная».
- Далее группа «Стили».
- Затем «Условное форматирование»;
- Нажать команду «Равно».
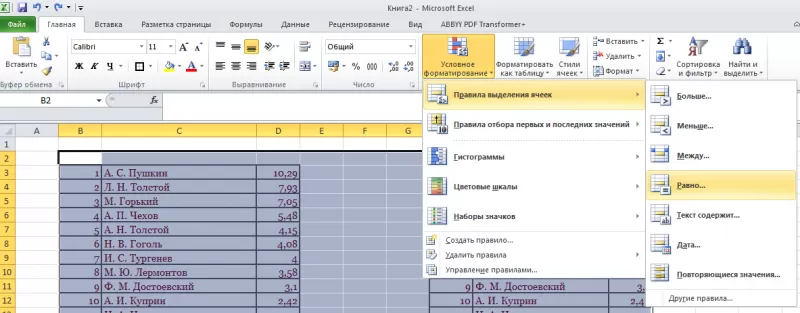
- Появится диалоговое окно:
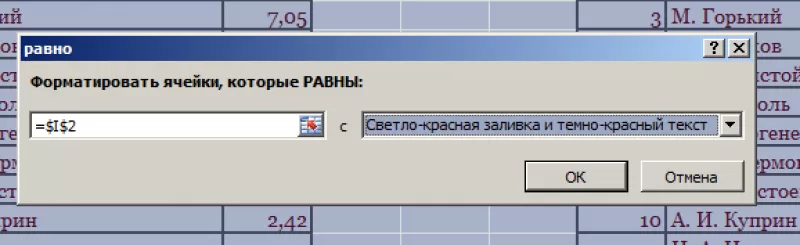
- В левом поле указать ячейку с I2, в которой записано «С. А. Есенин».
- В правом поле можно выбрать цвет шрифта.
- Нажать «ОК».
В таблицах отмечены цветом ячейки, значение которых равно заданному.
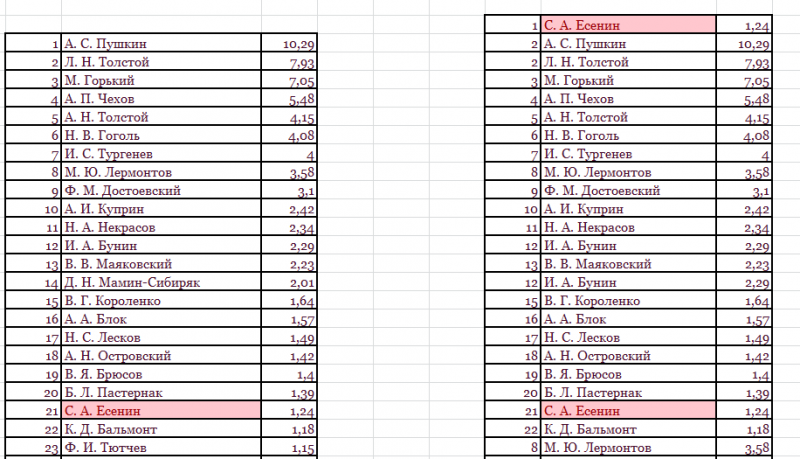
Несложно понять, как в Экселе найти одинаковые значения в столбце. Просто выделить перед поиском нужную область – конкретный столбец.
Ищем в таблицах Excel все повторяющиеся значения
Отметим все неуникальные записи в выделенной области. Для этого нужно:
- Зайти в группу «Стили».
- Далее «Условное форматирование».
- Теперь в выпадающем меню выбрать «Правила выделения ячеек».
- Затем «Повторяющиеся значения».
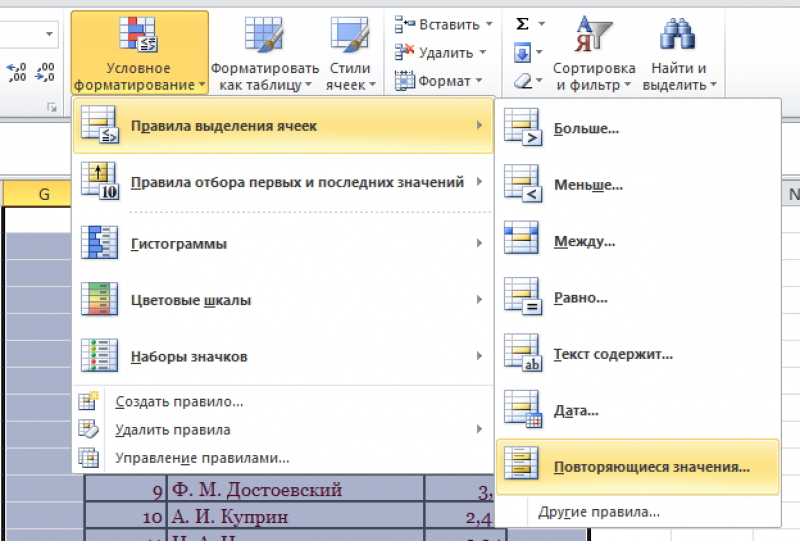
- Появится диалоговое окно:
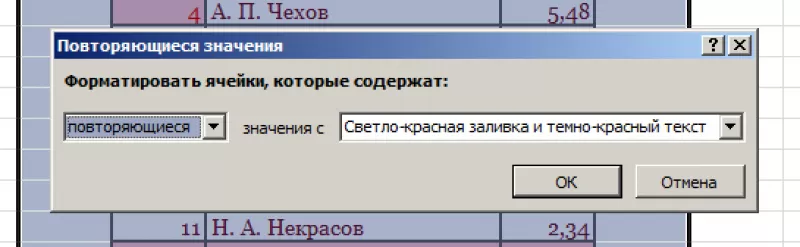
- Нажать «ОК».
Программа ищет повторения во всех столбцах.
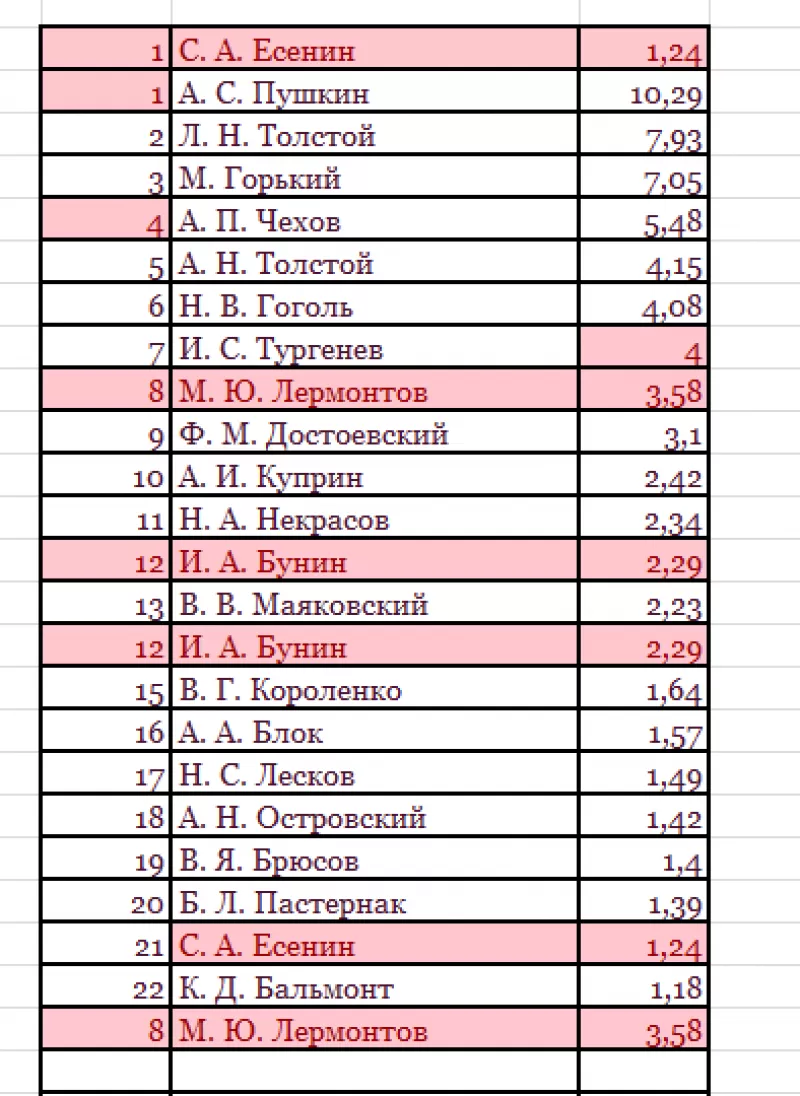
Если в таблице много неуникальных записей, то информативность такого поиска сомнительна.
Удаление одинаковых значений из таблицы Excel
Способ удаления неуникальных записей:
- Зайти во вкладку «Данные».
- Выделить столбец, в котором следует искать дублирующиеся строки.
- Опция «Удалить дубликаты».
В результате получаем список, в котором каждое имя фигурирует только один раз.
Список с уникальными значениями:

Расширенный фильтр: оставляем только уникальные записи
Расширенный фильтр – это инструмент для получения упорядоченного списка с уникальными записями.
- Выбрать вкладку «Данные».
- Перейти в раздел «Сортировка и фильтр».
- Нажать команду «Дополнительно»:
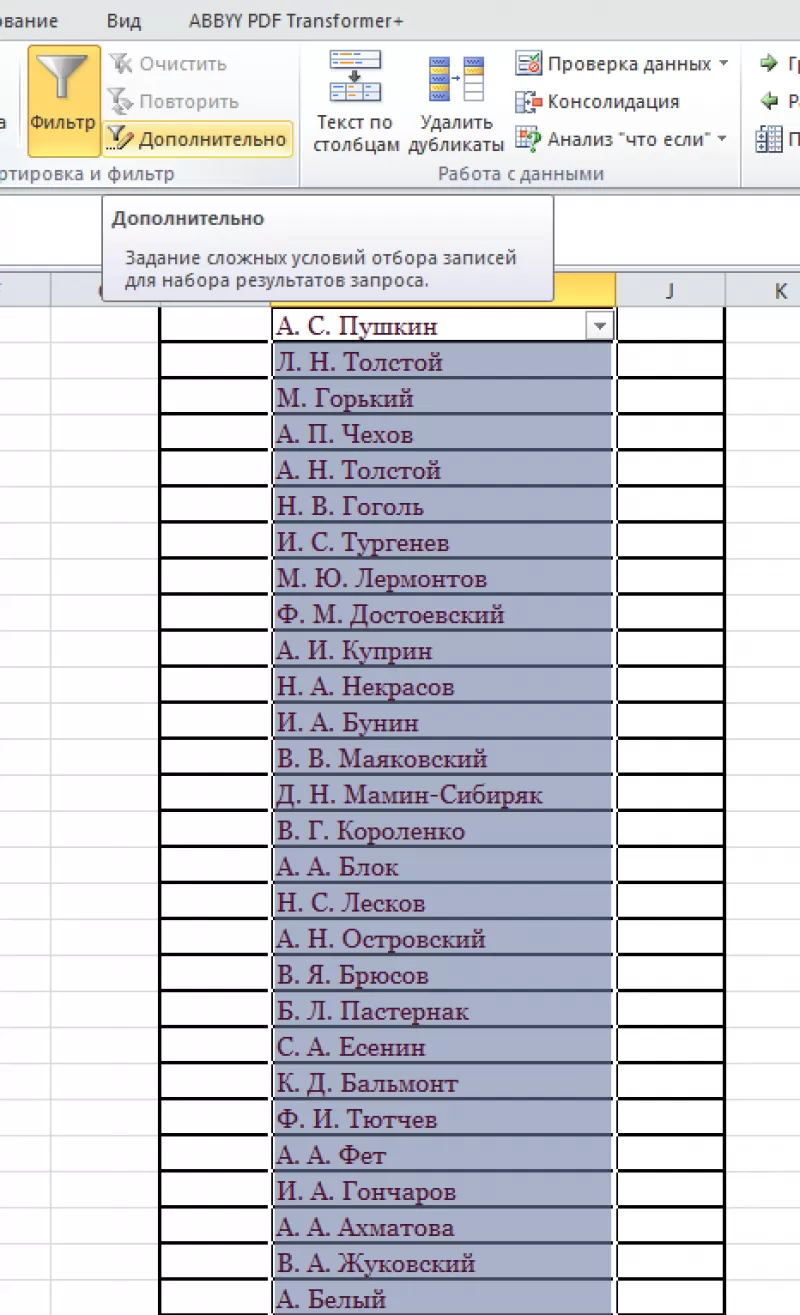
- В появившемся диалоговом окне ставим флажок «Только уникальные записи».
- Нажать «OK» – уникальный список готов.
Поиск дублирующихся значений с помощью сводных таблиц
Составим список уникальных строк, не теряя данные из других столбцов и не меняя исходную таблицу. Для этого используем инструмент Сводная таблица:
Пункт «Сводная таблица».
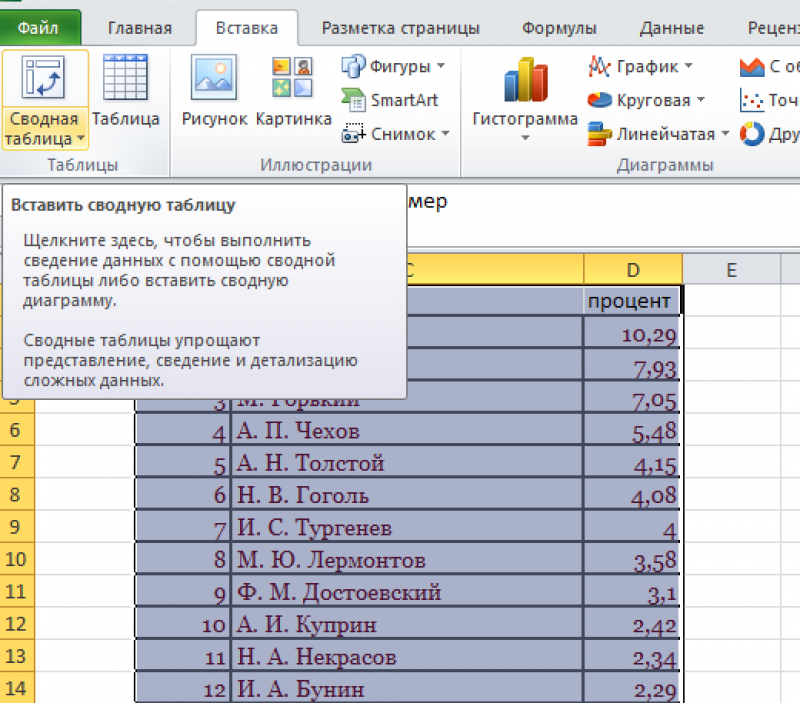
В диалоговом окне выбрать размещение сводной таблицы на новом листе.
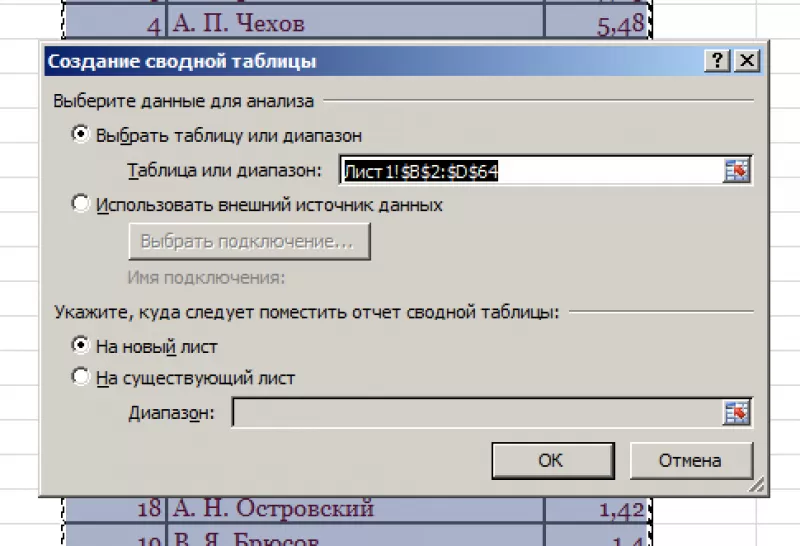
В открывшемся окне отмечаем столбец, в котором содержатся интересующие нас значений.
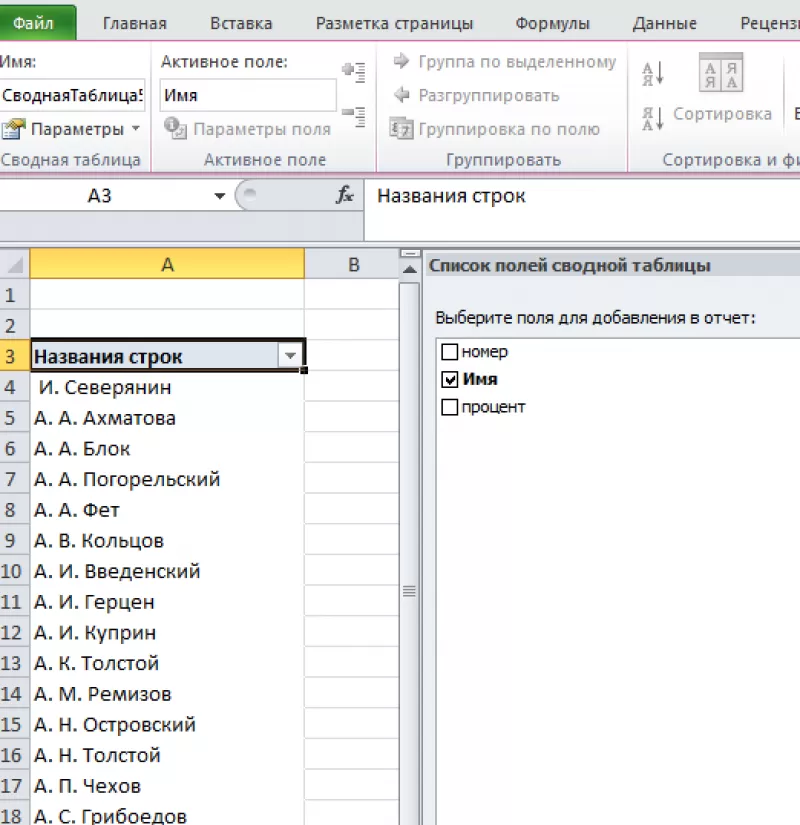
Получаем упорядоченный список уникальных строк.
Поиск и удаление дубликатов в Excel: 5 методов
Большие таблицы Эксель могут содержать повторяющиеся данные, что зачастую увеличивает объем информации и может привести к ошибкам в результате обработки данных при помощи формул и прочих инструментов. Это особенно критично, например, при работе с денежными и прочими финансовыми данными.
В данной статье мы рассмотрим методы поиска и удаления дублирующихся данных (дубликатов), в частности, строк в Excel.
Метод 1: удаление дублирующихся строк вручную
Первый метод максимально прост и предполагает удаление дублированных строк при помощи специального инструмента на ленте вкладки “Данные”.
- Полностью выделяем все ячейки таблицы с данными, воспользовавшись, например, зажатой левой кнопкой мыши.
- Во вкладке “Данные” в разделе инструментов “Работа с данными” находим кнопку “Удалить дубликаты” и кликаем на нее.


- Переходим к настройкам параметров удаления дубликатов:
- Если обрабатываемая таблица содержит шапку, то проверяем пункт “Мои данные содержат заголовки” – он должен быть отмечен галочкой.
- Ниже, в основном окне, перечислены названия столбцов, по которым будет осуществляться поиск дубликатов. Система считает совпадением ситуацию, в которой в строках повторяются значения всех выбранных в настройке столбцов. Если убрать часть столбцов из сравнения, повышается вероятность увеличения количества похожих строк.
- Тщательно все проверяем и нажимаем ОК.

- Далее программа Эксель в автоматическом режиме найдет и удалит все дублированные строки.
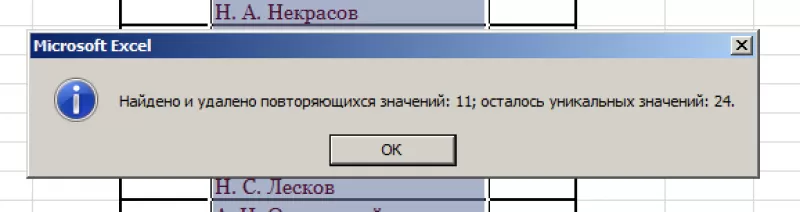
- По окончании процедуры на экране появится соответствующее сообщение с информацией о количестве найденных и удаленных дубликатов, а также о количестве оставшихся уникальных строк. Для закрытия окна и завершения работы данной функции нажимаем кнопку OK.

Метод 2: удаление повторений при помощи “умной таблицы”
Еще один способ удаления повторяющихся строк – использование “умной таблицы“. Давайте рассмотрим алгоритм пошагово.
- Для начала, нам нужно выделить всю таблицу, как в первом шаге предыдущего раздела.

- Во вкладке “Главная” находим кнопку “Форматировать как таблицу” (раздел инструментов “Стили“). Кликаем на стрелку вниз справа от названия кнопки и выбираем понравившуюся цветовую схему таблицы.

- После выбора стиля откроется окно настроек, в котором указывается диапазон для создания “умной таблицы“. Так как ячейки были выделены заранее, то следует просто убедиться, что в окошке указаны верные данные. Если это не так, то вносим исправления, проверяем, чтобы пункт “Таблица с заголовками” был отмечен галочкой и нажимаем ОК. На этом процесс создания “умной таблицы” завершен.

- Далее приступаем к основной задаче – нахождению задвоенных строк в таблице. Для этого:
- ставим курсор на произвольную ячейку таблицы;
- переключаемся во вкладку “Конструктор” (если после создания “умной таблицы” переход не был осуществлен автоматически);
- в разделе “Инструменты” жмем кнопку “Удалить дубликаты“.
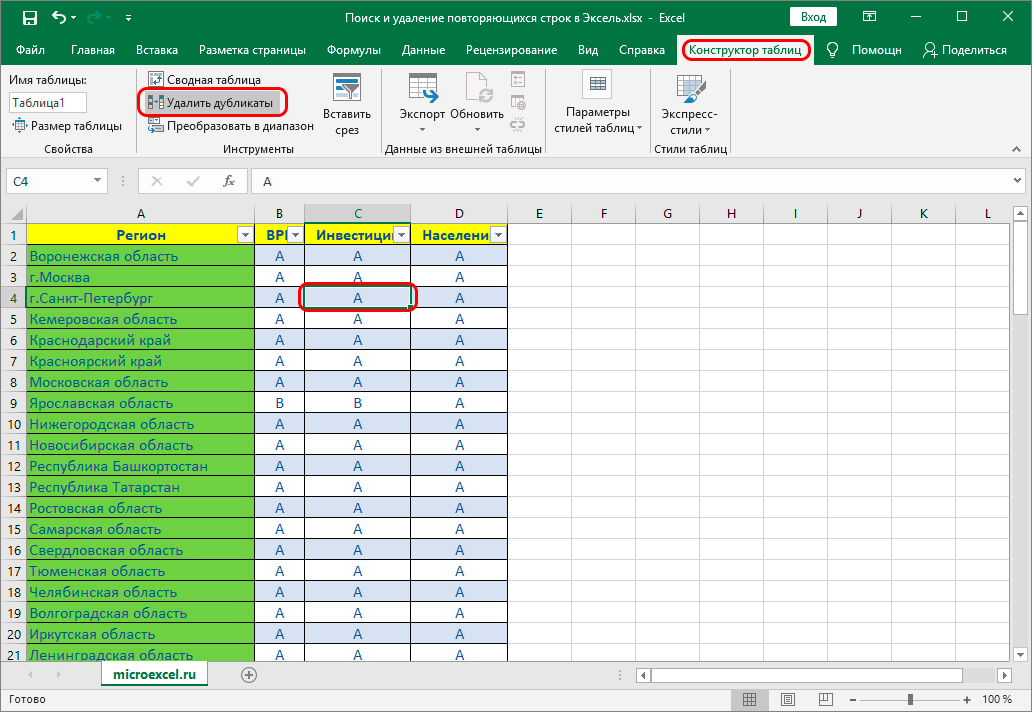
- Следующие шаги полностью совпадают с описанными в методе выше действиями по удалению дублированных строк.
Примечание: Из всех описываемых в данной статье методов этот является наиболее гибким и универсальным, позволяя комфортно работать с таблицами различной структуры и объема.
Метод 3: использование фильтра
Следующий метод не удаляет повторяющиеся строки физически, но позволяет настроить режим отображения таблицы таким образом, чтобы при просмотре они скрывались.
- Как обычно, выделяем все ячейки таблицы.
- Во вкладке “Данные” в разделе инструментов “Сортировка и фильтр” ищем кнопку “Фильтр” (иконка напоминает воронку) и кликаем на нее.

- После этого в строке с названиями столбцов таблицы появятся значки перевернутых треугольников (это значит, что фильтр включен). Чтобы перейти к расширенным настройкам, жмем кнопку “Дополнительно“, расположенную справа от кнопки “Фильтр“.

- В появившемся окне с расширенными настройками:
- как и в предыдущем способе, проверяем адрес диапазон ячеек таблицы;
- отмечаем галочкой пункт “Только уникальные записи“;
- жмем ОК.

- После этого все задвоенные данные перестанут отображаться в таблицей. Чтобы вернуться в стандартный режим, достаточно снова нажать на кнопку “Фильтр” во вкладке “Данные”.

Метод 4: условное форматирование
Условное форматирование – гибкий и мощный инструмент, используемый для решения широкого спектра задач в Excel. В этом примере мы будем использовать его для выбора задвоенных строк, после чего их можно удалить любым удобным способом.
- Выделяем все ячейки нашей таблицы.
- Во вкладке “Главная” кликаем по кнопке “Условное форматирование“, которая находится в разделе инструментов “Стили“.
- Откроется перечень, в котором выбираем группу “Правила выделения ячеек“, а внутри нее – пункт “Повторяющиеся значения“.

- Окно настроек форматирования оставляем без изменений. Единственный его параметр, который можно поменять в соответствии с собственными цветовыми предпочтениями – это используемая для заливки выделяемых строк цветовая схема. По готовности нажимаем кнопку ОК.

- Теперь все повторяющиеся ячейки в таблице “подсвечены”, и с ними можно работать – редактировать содержимое или удалить строки целиком любым удобным способом.
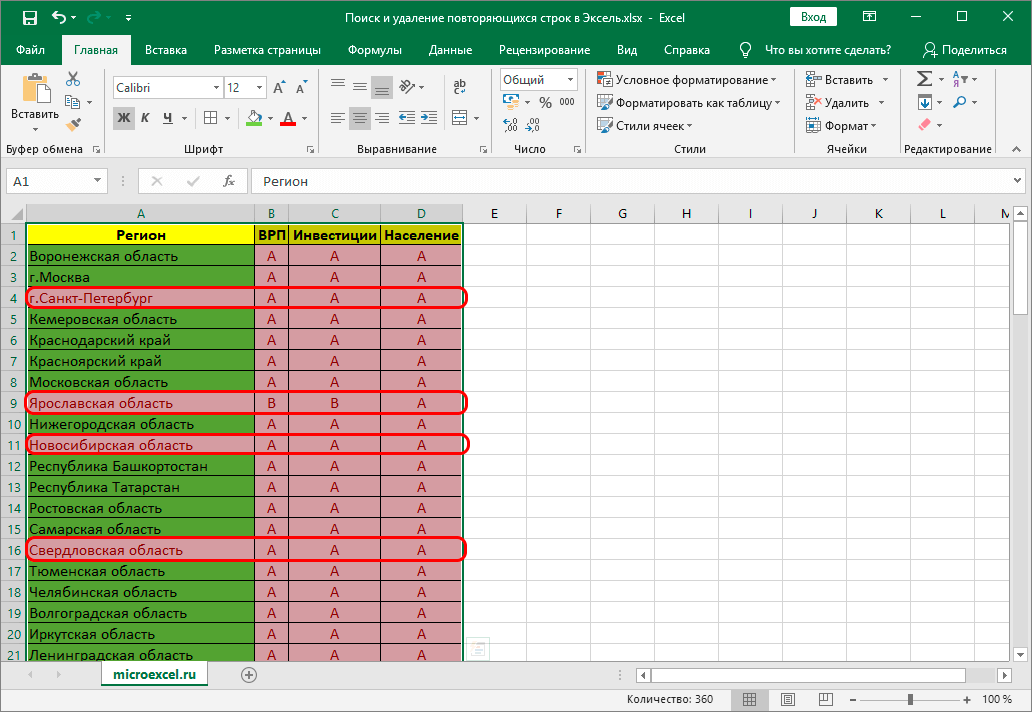
Важно! Этом метод не настолько универсален, как описанные выше, так как выделяет все ячейки с одинаковыми значениями, а не только те, для которых совпадает вся строка целиком. Это видно на предыдущем скриншоте, когда нужные задвоения по названиям регионов были выделены, но вместе с ними отмечены и все ячейки с категориями регионов, потому что значения этих категорий повторяются.
Метод 5: формула для удаления повторяющихся строк
Последний метод достаточно сложен, и им мало, кто пользуется, так как здесь предполагается использование сложной формулы, объединяющей в себе несколько простых функций. И чтобы настроить формулу для собственной таблицы с данными, нужен определенный опыт и навыки работы в Эксель.
Формула, позволяющая искать пересечения в пределах конкретного столбца в общем виде выглядит так:
Давайте посмотрим, как с ней работать на примере нашей таблицы:
- Добавляем в конце таблицы новый столбец, специально предназначенный для отображения повторяющихся значений (дубликаты).

- В верхнюю ячейку нового столбца (не считая шапки) вводим формулу, которая для данного конкретного примера будет иметь вид ниже, и жмем Enter:
=ЕСЛИОШИБКА(ИНДЕКС(A2:A90;ПОИСКПОЗ(0;СЧЁТЕСЛИ(E1:$E$1;A2:A90)+ЕСЛИ(СЧЁТЕСЛИ(A2:A90;A2:A90)>1;0;1);0));»») .
- Выделяем до конца новый столбец для задвоенных данных, шапку при этом не трогаем. Далее действуем строго по инструкции:
- ставим курсор в конец строки формул (нужно убедиться, что это, действительно, конец строки, так как в некоторых случаях длинная формула не помещается в пределах одной строки);
- жмем служебную клавишу F2 на клавиатуре;
- затем нажимаем сочетание клавиш Ctrl+SHIFT+Enter.
- Эти действия позволяют корректно заполнить формулой, содержащей ссылки на массивы, все ячейки столбца. Проверяем результат.

Как уже было сказано выше, этот метод сложен и функционально ограничен, так как не предполагает удаления найденных столбцов. Поэтому, при прочих равных условиях, рекомендуется использовать один из ранее описанных методов, более логически понятных и, зачастую, более эффективных.
Заключение
Excel предлагает несколько инструментов для нахождения и удаления строк или ячеек с одинаковыми данными. Каждый из описанных методов специфичен и имеет свои ограничения. К универсальным варианту мы, пожалуй, отнесем использование “умной таблицы” и функции “Удалить дубликаты”. В целом, для выполнения поставленной задачи необходимо руководствоваться как особенностями структуры таблицы, так и преследуемыми целями и видением конечного результата.
Как в Excel сравнить два столбца и удалить дубликаты (выделить, раскрасить, переместить)
Чтение этой статьи займёт у Вас около 10 минут. В следующие 5 минут Вы сможете легко сравнить два столбца в Excel и узнать о наличии в них дубликатов, удалить их или выделить цветом. Итак, время пошло!
Excel – это очень мощное и действительно крутое приложение для создания и обработки больших массивов данных. Если у Вас есть несколько рабочих книг с данными (или только одна огромная таблица), то, вероятно, Вы захотите сравнить 2 столбца, найти повторяющиеся значения, а затем совершить с ними какие-либо действия, например, удалить, выделить цветом или очистить содержимое. Столбцы могут находиться в одной таблице, быть смежными или не смежными, могут быть расположены на 2-х разных листах или даже в разных книгах.
Представьте, что у нас есть 2 столбца с именами людей – 5 имён в столбце A и 3 имени в столбце B. Необходимо сравнить имена в этих двух столбцах и найти повторяющиеся. Как Вы понимаете, это вымышленные данные, взятые исключительно для примера. В реальных таблицах мы имеем дело с тысячами, а то и с десятками тысяч записей.
Вариант А: оба столбца находятся на одном листе. Например, столбец A и столбец B.
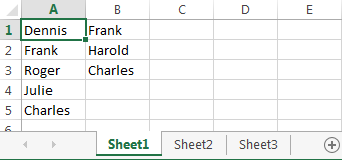
Вариант В: Столбцы расположены на разных листах. Например, столбец A на листе Sheet2 и столбец A на листе Sheet3.
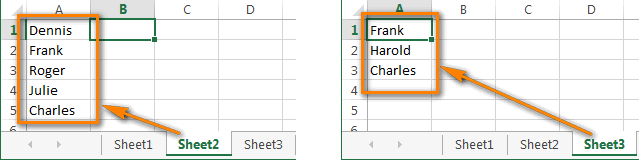
В Excel 2013, 2010 и 2007 есть встроенный инструмент Remove Duplicate (Удалить дубликаты), но он бессилен в такой ситуации, поскольку не может сравнивать данные в 2 столбцах. Более того, он может только удалить дубликаты. Других вариантов, таких как выделение или изменение цвета, не предусмотрено. И точка!
Далее я покажу Вам возможные пути сравнения двух столбцов в Excel, которые позволят найти и удалить повторяющиеся записи.
Сравниваем 2 столбца в Excel и находим повторяющиеся записи при помощи формул
Вариант А: оба столбца находятся на одном листе
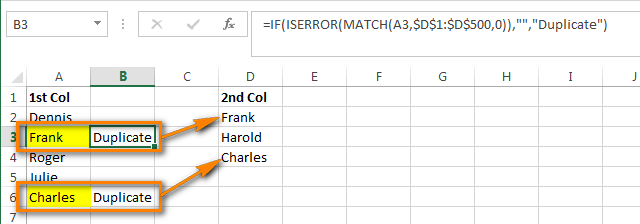
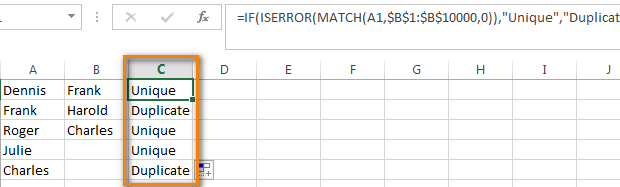
- В первой пустой ячейке (в нашем примере это ячейка C1) запишем вот такую формулу:
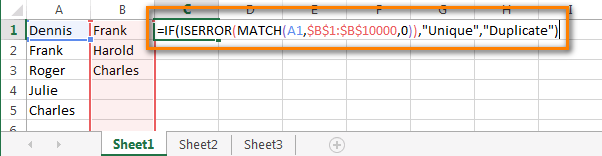
В нашей формуле A1 это первая ячейка первого столбца, который мы собираемся сравнивать. $B$1 и $B$10000 это адреса первой и последней ячеек второго столбца, с которым будем выполнять сравнение. Обратите внимание на абсолютные ссылки – буквам столбца и номерам строки предшествует знак доллара ($). Я использую абсолютные ссылки для того, чтобы адреса ячеек оставались неизменными при копировании формул.
Если Вы хотите найти дубликаты в столбце B, поменяйте ссылки, чтобы формула приняла такой вид:
Вместо “Unique” и “Duplicate” Вы можете записать собственные метки, например, “Не найдено” и “Найдено“, или оставить только “Duplicate” и ввести символ пробела вместо второго значения. В последнем случае ячейки, для которых дубликаты найдены не будут, останутся пустыми, и, я полагаю, такое представление данных наиболее удобно для дальнейшего анализа.
Теперь давайте скопируем нашу формулу во все ячейки столбца C, вплоть до самой нижней строки, которая содержит данные в столбце A. Для этого наведите указатель мыши на правый нижний угол ячейки C1, указатель примет форму чёрного перекрестия, как показано на картинке ниже: Нажмите и, удерживая левую кнопку мыши, протащите границу рамки вниз, выделяя все ячейки, в которые требуется вставить формулу. Когда все необходимые ячейки будут выделены, отпустите кнопку мыши:
Нажмите и, удерживая левую кнопку мыши, протащите границу рамки вниз, выделяя все ячейки, в которые требуется вставить формулу. Когда все необходимые ячейки будут выделены, отпустите кнопку мыши:
Подсказка: В больших таблицах скопировать формулу получится быстрее, если использовать комбинации клавиш. Выделите ячейку C1 и нажмите Ctrl+C (чтобы скопировать формулу в буфер обмена), затем нажмите Ctrl+Shift+End (чтобы выделить все не пустые ячейки в столбе С) и, наконец, нажмите Ctrl+V (чтобы вставить формулу во все выделенные ячейки).
- Отлично, теперь все повторяющиеся значения отмечены как “Duplicate“:
Вариант В: два столбца находятся на разных листах (в разных книгах)
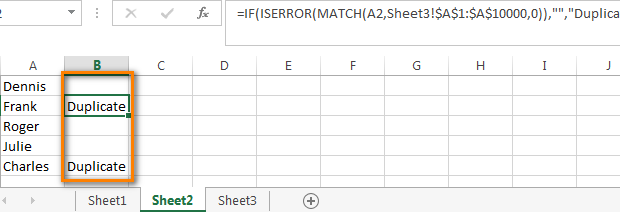
- В первой ячейке первого пустого столбца на листе Sheet2 (в нашем случае это столбец В) введите такую формулу:
Здесь Sheet3 – это название листа, на котором расположен 2-ой столбец, а $A$1:$A$10000 – это адреса ячеек от 1-ой до последней в этом 2-ом столбце.
Обработка найденных дубликатов
Отлично, мы нашли записи в первом столбце, которые также присутствуют во втором столбце. Теперь нам нужно что-то с ними делать. Просматривать все повторяющиеся записи в таблице вручную довольно неэффективно и занимает слишком много времени. Существуют пути получше.
Показать только повторяющиеся строки в столбце А
Если Ваши столбцы не имеют заголовков, то их необходимо добавить. Для этого поместите курсор на число, обозначающее первую строку, при этом он превратится в чёрную стрелку, как показано на рисунке ниже:

Кликните правой кнопкой мыши и в контекстном меню выберите Insert (Вставить):
Дайте названия столбцам, например, “Name” и “Duplicate?” Затем откройте вкладку Data (Данные) и нажмите Filter (Фильтр):
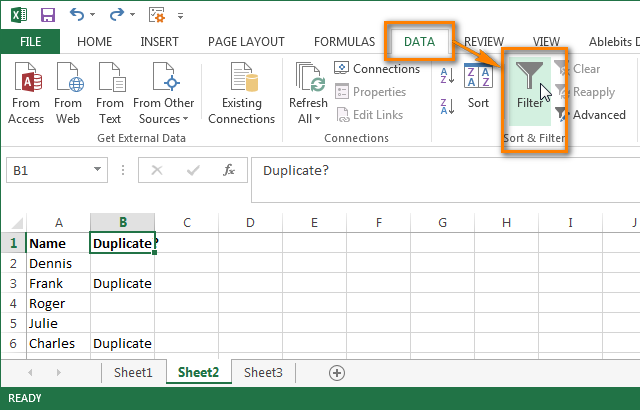
После этого нажмите меленькую серую стрелку рядом с “Duplicate?“, чтобы раскрыть меню фильтра; снимите галочки со всех элементов этого списка, кроме Duplicate, и нажмите ОК.
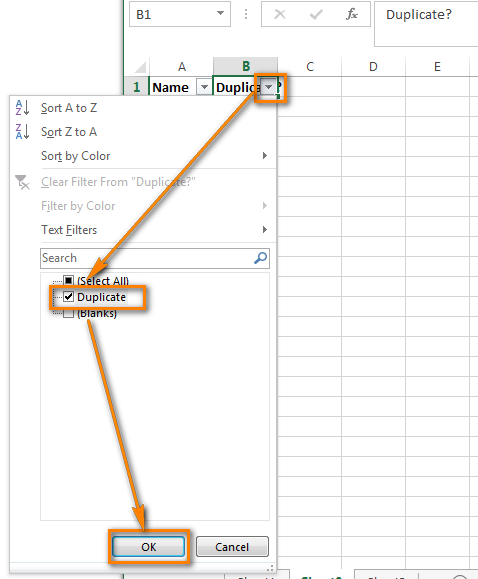
Вот и всё, теперь Вы видите только те элементы столбца А, которые дублируются в столбце В. В нашей учебной таблице таких ячеек всего две, но, как Вы понимаете, на практике их встретится намного больше.
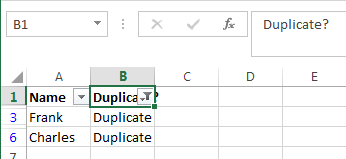
Чтобы снова отобразить все строки столбца А, кликните символ фильтра в столбце В, который теперь выглядит как воронка с маленькой стрелочкой и выберите Select all (Выделить все). Либо Вы можете сделать то же самое через Ленту, нажав Data (Данные) > Select & Filter (Сортировка и фильтр) > Clear (Очистить), как показано на снимке экрана ниже:
Изменение цвета или выделение найденных дубликатов
Если пометки “Duplicate” не достаточно для Ваших целей, и Вы хотите отметить повторяющиеся ячейки другим цветом шрифта, заливки или каким-либо другим способом…
В этом случае отфильтруйте дубликаты, как показано выше, выделите все отфильтрованные ячейки и нажмите Ctrl+1, чтобы открыть диалоговое окно Format Cells (Формат ячеек). В качестве примера, давайте изменим цвет заливки ячеек в строках с дубликатами на ярко-жёлтый. Конечно, Вы можете изменить цвет заливки при помощи инструмента Fill (Цвет заливки) на вкладке Home (Главная), но преимущество диалогового окна Format Cells (Формат ячеек) в том, что можно настроить одновременно все параметры форматирования.
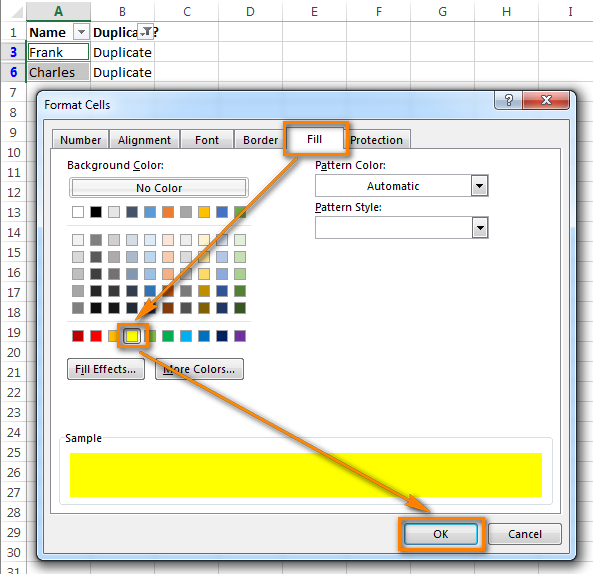
Теперь Вы точно не пропустите ни одной ячейки с дубликатами:
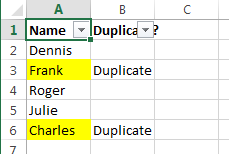
Удаление повторяющихся значений из первого столбца
Отфильтруйте таблицу так, чтобы показаны были только ячейки с повторяющимися значениями, и выделите эти ячейки.
Если 2 столбца, которые Вы сравниваете, находятся на разных листах, то есть в разных таблицах, кликните правой кнопкой мыши выделенный диапазон и в контекстном меню выберите Delete Row (Удалить строку):
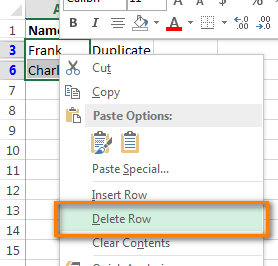
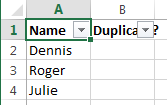
Нажмите ОК, когда Excel попросит Вас подтвердить, что Вы действительно хотите удалить всю строку листа и после этого очистите фильтр. Как видите, остались только строки с уникальными значениями:
Если 2 столбца расположены на одном листе, вплотную друг другу (смежные) или не вплотную друг к другу (не смежные), то процесс удаления дубликатов будет чуть сложнее. Мы не можем удалить всю строку с повторяющимися значениями, поскольку так мы удалим ячейки и из второго столбца тоже. Итак, чтобы оставить только уникальные записи в столбце А, сделайте следующее:
- Отфильтруйте таблицу так, чтобы отображались только дублирующиеся значения, и выделите эти ячейки. Кликните по ним правой кнопкой мыши и в контекстном меню выберите Clear contents (Очистить содержимое).
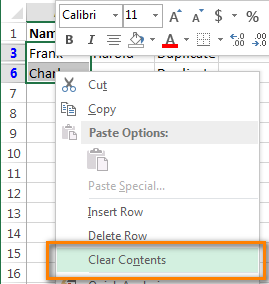
- Очистите фильтр.
- Выделите все ячейки в столбце А, начиная с ячейки А1 вплоть до самой нижней, содержащей данные.
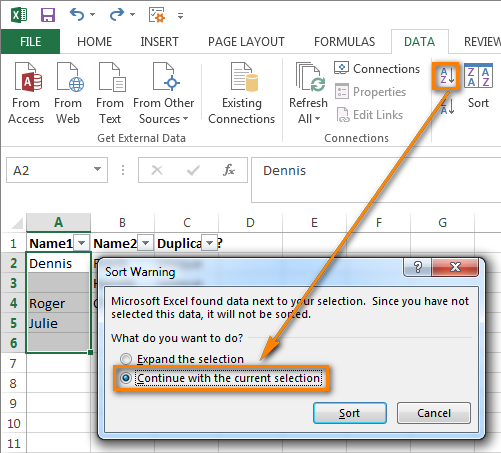
- Откройте вкладку Data (Данные) и нажмите Sort A to Z (Сортировка от А до Я). В открывшемся диалоговом окне выберите пункт Continue with the current selection (Сортировать в пределах указанного выделения) и нажмите кнопку Sort (Сортировка):
- Удалите столбец с формулой, он Вам больше не понадобится, с этого момента у Вас остались только уникальные значения.
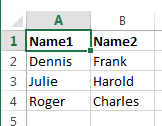
- Вот и всё, теперь столбец А содержит только уникальные данные, которых нет в столбце В:
Как видите, удалить дубликаты из двух столбцов в Excel при помощи формул – это не так уж сложно.

