

Посчитать ошибку прогноза
4. Решение типовых задач
По районам региона приводятся данные за 200Х г. (табл. 1.1).
Среднедушевой прожиточный минимум в день одного трудоспособного, руб., Х
Среднедневная заработная плата, руб., У
1. Построить линейное уравнение парной регрессии у от х.
2. Рассчитать линейный коэффициент парной корреляции и среднюю ошибку аппроксимации.
3. Оценить статистическую значимость параметров регрессии и корреляции.
4. Выполнить прогноз заработной платы у при прогнозном значении среднедушевого прожиточного минимума х, составляющем 107% от среднего уровня.
5. Оценить точность прогноза, рассчитав ошибку прогноза и его доверительный интервал.
1. Для расчета параметров уравнения линейной регрессии строим расчетную таблицу (табл. 1.2).
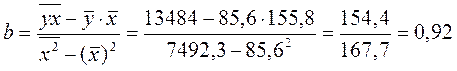 ;
;

YI—
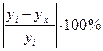
. 
Получено уравнение регрессии:  .
.
С увеличением среднедушевого прожиточного минимума на 1 руб. среднедневная заработная плата возрастает в среднем на 0,92 руб.
2. Тесноту линейной связи оценит коэффициент корреляции:
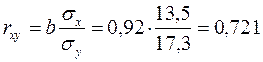 ;
;  .
.
Это означает, что 52% вариации заработной платы (у) объясняется вариацией фактора х – среднедушевого прожиточного минимума.
Качество модели определяет средняя ошибка аппроксимации:
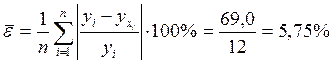 .
.
Качество построенной модели оценивается как хорошее, так как средняя относительная ошибка аппроксимации не превышает 8-10%.
3. Оценку статистической значимости параметров регрессии проведем с помощью t-статистики Стьюдента и путем расчета доверительного интервала каждого из показателей.
Выдвигаем гипотезу Н0 о статистически незначимом отличии показателя от нуля:  .
.
Определим случайные ошибки Ma, mb,  :
:
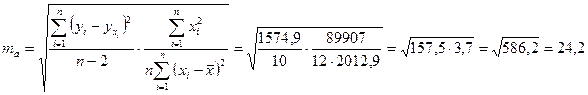 ;
;
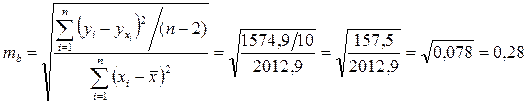 ;
;
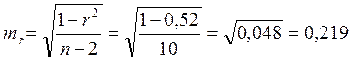 .
.
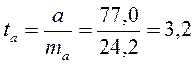 ;
; 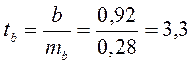 ;
;
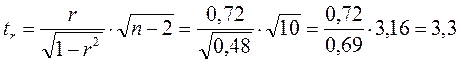 .
.
Фактические значения t-статистики превосходят табличные значения:
 ;
;  ;
;  ,
,
Поэтому гипотеза Н0 отклоняется, т. е. A, B и Rxy не случайно отличаются от нуля, а статистически значимы.
Рассчитаем доверительный интервал для A и B. Для этого определим предельную ошибку для каждого показателя:
 ;
;  .
.
 ;
;
 ;
;
 ;
;
 ;
;
 ;
;
 .
.
Анализ верхней и нижней границ доверительных интервалов приводит к выводу о том, что с вероятностью  параметры A и B, находясь в указанных границах, не принимают нулевые значения, т. е. не являются статистики незначимыми и существенно отличаются от нуля.
параметры A и B, находясь в указанных границах, не принимают нулевые значения, т. е. не являются статистики незначимыми и существенно отличаются от нуля.
4. Полученные оценки уравнения регрессии позволяют использовать его для прогноза. Если прогнозное значение промежуточного минимума составит:  тыс. руб., тогда прогнозное значение прожиточного минимума составит:
тыс. руб., тогда прогнозное значение прожиточного минимума составит:  тыс. руб.
тыс. руб.
5. Ошибка прогноза составит:
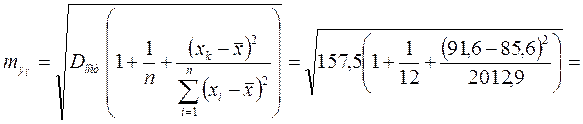
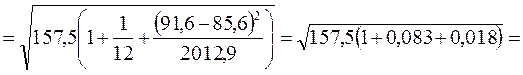
 тыс. руб.
тыс. руб.
Предельная ошибка прогноза, которая в 95% случаев не будет превышена, составит:
 .
.
Доверительный интервал прогноза:
 ;
;
 руб.;
руб.;
 руб.
руб.
Выполненный прогноз среднемесячной заработной платы оказался надежным, но неточным, т. к. диапазон верхней и нижней границ доверительного интервала составляет 1,95 раза (121/62,2).
Зависимость потребления продукта А от среднедушевого дохода по данным 20 семей характеризуется следующим образом:
— уравнение регрессии  ;
;
— индекс корреляции  ;
;
— остаточная дисперсия  .
.
Требуется провести дисперсионный анализ полученных результатов.
Результаты дисперсионного анализа приведены в табл. 1.3.
Почему мы не считаем MAPE, RMSE и другие математические ошибки при прогнозировании спроса
Когда перед компанией встают задачи прогнозирования спроса для управления товарными запасами, обычно появляется вопрос, связанный с выбором метода прогнозирования. Но как определить, какой метод лучше? Однозначного ответа на этот вопрос нет. Однако, исходя из нашей практики, самым распространенным методам оценки точности прогноза является средняя абсолютная процентная ошибка (MAPE). Также используются средняя абсолютная ошибка (MAE) и средняя квадратичная ошибка прогнозирования (RMSE).
Ошибка прогноза в данном случае – это разница между фактическим значением спроса и его прогнозным значением. Т.е, чем больше будет ошибка прогнозирования, тем менее точен прогноз. Например, при ошибке прогнозирования 5%, точность прогноза будет составлять 95%. Изначально MAPE использовалась для прогнозирования временных рядов, которые имеют регулярное нормальное распределение, такие как, например, потребление электроэнергии. И только после ее стали применять для оценки прогноза спроса. На практике ошибку могут рассчитывать по каждой позиции товара, а также среднюю оценку по всем товарным группам.
Несмотря на то, что большинство компаний до сих пор используют вышеописанные методы для оценки, мы считаем, что они не достаточно корректны и не подходят для применения в реальном бизнесе. Для простоты изложения, выделим три ключевых момента, которые приводят к некорректным выводам при использовании вышеописанных методов оценки. Назовем их ошибка №1, №2 и №3. Сначала мы подробно опишем эти ошибки, а потом расскажем, как наши методы сравнения помогаю их ликвидировать.
О некорректности использования MAPE, RMSE и других распространенных ошибок
Ошибка № 1 заключается в том, что используемые методы больше относятся к математике, нежели к бизнесу, по той причине, что это обезличенные цифры (или проценты), которые ничего не говорят про деньги. Бизнесу же нужно принимать решения на основе выгоды, которую он получит в деньгах. Например, ошибка в 80% на первый взгляд звучит устрашающие. Но в реальности за ней могут скрываться совершенно разные вещи. Ошибка по гвоздям со стоимостью одного гвоздя в 0,5 рублей – это одни потери. Но они совершенно несопоставимы с потерями от продажи промышленного оборудования стоимостью 700 000 рублей с той же величиной ошибки прогнозирования. Ко всему прочему также больше значение имеет объем продукции, что тоже никак не учитывается данными ошибками прогнозирования.
Второй важный момент (ошибка №2), который не учитывают данные оценки прогнозирования – это заморозка денежных средств в запасах и недополученная прибыль от дефицита продукции на складе. Например, если мы прогнозируем продажу 20 колесных дисков, а по факту продали 15. То это одна цена ошибки – 5 колесных дисков, которые потребуют затраты на хранение на определенное время, и как следствие стоимость замороженных оборотных средств под определенный процент. Если рассмотреть обратную ситуацию – прогнозируем продажу 20 дисков, спрос составляет 25 штук. Это уже упущенная прибыль, которая составляет разницу сумм закупки и реализации продукции. По сути мы имеет одну и ту же ошибку прогнозирования, но результат от нее может быть совершенно разным.
Третий ключевой момент (ошибка №3) – описанные ошибки распространяются только на точечный прогноз спроса и не описывают страховой запас. А он в некоторых случаях может составлять от 20% до 70% от общих товарных запасов на складе. Поэтому, какой бы точный не был прогноз с точки зрения описанных выше методов, мы все равно не оцениваем точность страхового запаса, а значит реальные данные могут быть значительно искажены.
Критерии, привязанные к прибыльности бизнеса
Учитывая описанные выше недостатки ошибок прогнозирования, такой подход не является корректным и надежным для сравнения алгоритмов. Ко всему прочему он зачастую оторван от реального бизнеса. Используемый же нами подход позволяет оценить точность алгоритмов в деньгах, рассчитать стоимость ошибки прогнозирования на понятном для бизнеса языке финансов. Таким образом это позволяет нам ликвидировать ошибку №1.
В случае с ошибкой № 2, мы рассчитываем два различных значения. Если прогноз окажется меньше реального спроса, то он приведет к дефициту, экономический урон от которого рассчитывается, как количество недопроданных товаров, умноженное на разность цен закупки и реализации. Например, вы закупаете колесные диски по 3000 рублей за штуку и продаете по 4000. Прогноз на месяц составил 1000 дисков, реальный спрос оказался 1200 штук. Экономический урон будет равен:
(1200-1000)*(4000-3000)=200 000 рублей.
В случае превышения прогноза над реальным спросом компания понесет убытки по хранению продукции. Экономический урон будет равен сумме затрат на нереализованную продукцию, помноженную на ставку альтернативных вложений за этот период. Предположим, что реальный спрос в предыдущем примере оказался 800 дисков и вам пришлось хранить диски еще один месяц. Пусть ставка альтернативных вложений составляет 20% в год. Тогда экономический урон будет равен
(1000-800)*3000*0,2/12=10 000 рублей.
Соответственно, в каждом конкретном случае, мы будет учитывать одно из этих значений.
Для того, чтобы ликвидировать ошибку № 3, мы сравниваем алгоритмы с использованием понятия уровень сервиса. Уровень сервиса (здесь и далее — уровень сервиса II рода, fill rate) – это доля спроса, которую мы гарантировано покроем с использованием имеющихся на складе запасов в течении периода их пополнения. Например, уровень сервиса 90% означает, что мы удовлетворим 90% спроса. На первый взгляд может показаться логичным, что уровень сервиса всегда должен составлять 100%. Тогда и прибыль будет максимальна. Но в реальных ситуациях зачастую дело обстоит иначе: удовлетворение 100% уровня сервиса приводит к сильному перезатариванию склада, а для товаров с ограниченными сроками годности еще и к списанию. И убытки от затрат на хранение, списания просроченной продукции и недополученной прибыли от вложения свободных денег в итоге снизят прибыть от реализации, в случае если бы мы поддерживали уровень сервиса 95%. Нужно заметить, что для каждой отдельной позиции товаров будет свой оптимальный уровень сервиса.
Подробнее о уровне сервиса, его видах и примерах расчета читайте в статье «Что такое уровень сервиса и почему он важен.»
Так как страховой запас может составлять значительную долю, его нельзя игнорировать при сравнении алгоритмов (как это делается при расчете ошибок MAPE, RMSE и т.д.). Поэтому мы делаем сравнение не прогноза, а оптимального запаса с заданным уровнем сервиса. Оптимальный запас для заданного уровня сервиса – это такое количество товаров, которое нужно хранить на складе, чтобы получить максимум прибыли от реализации товаров и одновременно сократить издержки на хранение до минимума.
В качестве основного критерия (критерий №1) качества прогнозирования мы используем суммарное значение потерь для заданного уровня сервиса, о котором писали выше (исправление ошибки №2). Таким образом мы оцениваем потери в денежном выражении при использовании данного конкретного алгоритма. Чем меньше потери — тем точнее работает алгоритм.
Здесь нужно заметить, что для разных уровней сервиса оптимальный запас тоже может различаться. И в одном случае прогноз будет точно в него попадать, а в другом возможны перекосы в большую, либо меньшую сторону. Так как многие компании не рассчитывают оптимальный уровень сервиса, а используют заданный заранее, значение основного критерия мы вычисляем для всех самых распространенных уровней сервиса: 70%, 75%, 80%, 85%, 90%, 95%, 98%, 99% и суммируем потери. Таким образом мы можем проверить, насколько хорошо в целом работает модель.
Для компаний, которые, считают оптимальный уровень сервиса мы используем дополнительный критерий (критерий №2) для оценки. В общем виде он выглядит как соотношение потерь на оптимальном уровне сервиса по ожидаемому (модельному) распределению продаж и по реальному распределению продаж (по факту). Прогнозируемое значение оптимального уровня сервиса не всегда соответствует оптимальному значению уже на реальном распределении продаж. Поэтому мы должны сравнивать ошибку между прогнозом объема продаж на оптимальном (по модели) уровне сервиса и реальным объемом продаж, обеспечивающим оптимальное значение уровня сервиса по реальным данным.
Что проиллюстрировать применение данного критерия, вернемся к нашему примеру с дисками. Предположим, что прогнозное значение оптимального уровня сервиса для него составляет 90%, а оптимальный объем запаса для этого случая примем равным 3000 колесных дисков. Пусть в первом случае реальный уровень сервиса оказался выше прогнозного и составил 92%. Соответственно объем заказов также вырос и составил 3300 дисков. Ошибка прогнозирования будет рассчитываться как разность между реальным и фактическим объемом продаж, умноженная на разность цен реализации. Итого, мы имеем:
(3300-3000)*(4000-3000)=300 000 рублей.
Теперь представим обратную ситуацию: реальный уровень сервиса оказался меньше прогнозного и составил 87%. Реальный объем продаж при этом составил 2850 дисков. Ошибка прогнозирования будет рассчитана, как сумма затрат на нереализованную продукцию, умноженную на ставку альтернативных вложений за этот период (в качестве примера берем период сроком месяц и ставку равную 20% годовых). Итоговое значение критерия будет равно:
(3000-2850)*3000*0,2/12 = 7500 рублей
Конечно, в идеальном случае, мы должны рассчитывать ошибку только при оптимальном уровне сервиса, между прогнозным и реальным значениями. Но так как не все компании еще перешли на оптимальный уровень сервиса, мы вынуждены использовать два критерия.
Используемые нами критерии в отличие от классических математических ошибок, показывают суммарные потери в деньгах при применении той или иной модели. Соответственно, наилучшей будет модель, которая обеспечивает минимальные потери. Такой подход позволят бизнес-пользователям оценить работу различных алгоритмов на понятном им языке.
Пример сравнения точности прогнозирования системы Forecast NOW c методом ARIMA (на базе номенклатуры бытовой химии):
Методы оценки качества прогноза
Часто при составлении любого прогноза — забывают про способы оценки его результатов. Потому как часто бывает, прогноз есть, а сравнение его с фактом отсутствует. Еще больше ошибок случается, когда существуют две (или больше) модели и не всегда очевидно — какая из них лучше, точнее. Как правило одной цифрой (R 2 ) сложно обойтись. Как если бы вам сказали — этот парень ходит в синей футболке. И вам сразу все стало про него ясно )
В статьях о методах прогнозирования при оценке полученной модели я постоянно использовал такие аббревиатуры или обозначения.
- R 2
- MSE
- MAPE
- MAD
- Bias
Попробую объяснить, что я имел в виду.
Остатки
Суровые MSE и R 2
Когда нам требуется подогнать кривую под наши данные, то точность этой подгонки будет оцениваться программой по среднеквадратической ошибке (mean squared error, MSE). Рассчитывается по незамысловатой формуле 
где n-количество наблюдений.
Соотвественно, программа, рассчитывая кривую подгонки, стремится минимизировать этот коэффициент. Квадраты остатков в числителе взяты именно по той причине, чтобы плюсы и минусы не взаимоуничтожились. Физического смысла MSE не имеет, но чем ближе к нулю, тем модель лучше.
Вторая абстрактная величина это R 2 — коэффициент детерминации. Характеризует степень сходства исходных данных и предсказанных. В отличии от MSE не зависит от единиц измерения данных, поэтому поддается сравнению. Рассчитывается коэффициент по следующей формуле: 
где Var(Y) — дисперсия исходных данных.
Безусловно коэффициент детерминации — важный критерий выбора модели. И если модель плохо коррелирует с исходными данными, она вряд ли будет иметь высокую предсказательную силу. 
MAPE и MAD для сравнения моделей
Статистические методы оценки моделей вроде MSE и R 2 , к сожалению, трудно интерпретировать, поэтому светлые головы придумали облегченные, но удобные для сравнения коэффициенты.
Среднее абсолютное отклонение (mean absolute deviation, MAD) определяется как частное от суммы остатков по модулю к числу наблюдений. То есть, средний остаток по модулю. Удобно? Вроде да, а вроде и не очень. В моем примере MAD=43. Выраженный в абсолютных единицах MAD показывает насколько единиц в среднем будет ошибаться прогноз.
MAPE призван придать модели еще более наглядный смысл. Расшифровывается выражение как средняя абсолютная ошибка в процентах (mean percentage absolute error, MAPE). 
где Y — значение исходного ряда.
Выражается MAPE в процентах, и в моем случае означает, что в модель может ошибаться в среднем на 16%. Что, согласитесь, вполне допустимо.
Наконец, последняя абсолютно синтетическая величина — это Bias, или просто смещение. Дело в том, что в реальном мире отклонения в одну сторону зачастую гораздо болезненнее, чем в другую. К примеру, при условно неограниченных складских помещениях, важнее учитывать скачки реального спроса вверх от спрогнозированных значений. Поэтому случаи, где остатки положительные относятся к общему числу наблюдений. В моем случае 44% спрогнозированных значений оказались ниже исходных. И можно пожертвовать другими критериями оценки, чтобы минимизировать этот Bias.
Можете попробовать это сами в  Excel и Numbers
Excel и Numbers
Интересно узнать — какие методы оценки качества прогнозирования вы используете в своей работе?
Ошибка прогнозирования: виды, формулы, примеры
Ошибка прогнозирования — это такая величина, которая показывает, как сильно прогнозное значение отклонилось от фактического. Она используется для расчета точности прогнозирования, что в свою очередь помогает нам оценивать как точно и корректно мы сформировали прогноз. В данной статье я расскажу про основные процентные «ошибки прогнозирования» с кратким описанием и формулой для расчета. А в конце статьи я приведу общий пример расчётов в Excel. Напомню, что в своих расчетах я в основном использую ошибку WAPE или MAD-Mean Ratio, о которой подробно я рассказал в статье про точность прогнозирования, здесь она также будет упомянута.
В каждой формуле буквой Ф обозначено фактическое значение, а буквой П — прогнозное. Каждая ошибка прогнозирования (кроме последней!), может использоваться для нахождения общей точности прогнозирования некоторого списка позиций, по типу того, что изображен ниже (либо для любого другого подобной детализации):
Алгоритм для нахождения любой из ошибок прогнозирования для такого списка примерно одинаковый: сначала находим ошибку прогнозирования по одной позиции, а затем рассчитываем общую. Итак, основные ошибки прогнозирования!
MPE — Mean Percent Error
MPE — средняя процентная ошибка прогнозирования. Основная проблема данной ошибки заключается в том, что в нестабильном числовом ряду с большими выбросами любое незначительное колебание факта или прогноза может значительно поменять показатель ошибки и, как следствие, точности прогнозирования. Помимо этого, ошибка является несимметричной: одинаковые отклонения в плюс и в минус по-разному влияют на показатель ошибки.
- Для каждой позиции рассчитывается ошибка прогноза (факт вычитается из прогноза) — Error
- Для каждой позиции рассчитывается процентная ошибка прогноза (ошибка прогноза делится на фактический показатель) — Percent Error
- Находится среднее арифметическое всех процентных ошибок прогноза (процентные ошибки суммируются и делятся на количество) — Mean Percent Error
MAPE — Mean Absolute Percent Error
MAPE — средняя абсолютная процентная ошибка прогнозирования. Основная проблема данной ошибки такая же, как и у MPE — нестабильность.
- Для каждой позиции рассчитывается абсолютная ошибка прогноза (факт вычитается из прогноза по модулю) — Absolute Error
- Для каждой позиции рассчитывается абсолютная процентная ошибка прогноза (абсолютная ошибка прогноза делится на фактический показатель) — Absolute Percent Error
- Находится среднее арифметическое всех абсолютных процентных ошибок прогноза (абсолютные процентные ошибки суммируются и делятся на количество) — Mean Absolute Percent Error
Вместо среднего арифметического всех абсолютных процентных ошибок прогноза можно использовать медиану числового ряда (MdAPE — Median Absolute Percent Error), она наиболее устойчива к выбросам.
WMAPE / MAD-Mean Ratio / WAPE — Weighted Absolute Percent Error
WAPE — взвешенная абсолютная процентная ошибка прогнозирования. Одна из «лучших ошибок» для расчета точности прогнозирования. Часто называется как MAD-Mean Ratio, то есть отношение MAD (Mean Absolute Deviation — среднее абсолютное отклонение/ошибка) к Mean (среднее арифметическое). После упрощения дроби получается искомая формула WAPE, которая очень проста в понимании:
- Для каждой позиции рассчитывается абсолютная ошибка прогноза (факт вычитается из прогноза, по модулю) — Absolute Error
- Находится сумма всех фактов по всем позициям (общий фактический объем)
- Сумма всех абсолютных ошибок делится на сумму всех фактов — WAPE
Данная ошибка прогнозирования является симметричной и наименее чувствительна к искажениям числового ряда.
Рекомендуется к использованию при расчете точности прогнозирования. Более подробно читать здесь.
RMSE (as %) / nRMSE — Root Mean Square Error
RMSE — среднеквадратичная ошибка прогнозирования. Примерно такая же проблема, как и в MPE и MAPE: так как каждое отклонение возводится в квадрат, любое небольшое отклонение может значительно повлиять на показатель ошибки. Стоит отметить, что существует также ошибка MSE, из которой RMSE как раз и получается путем извлечения корня. Но так как MSE дает расчетные единицы измерения в квадрате, то использовать данную ошибку будет немного неправильно.
- Для каждой позиции рассчитывается квадрат отклонений (разница между фактом и прогнозом, возведенная в квадрат) — Square Error
- Затем рассчитывается среднее арифметическое (сумма квадратов отклонений, деленное на количество) — MSE — Mean Square Error
- Извлекаем корень из полученного результат — RMSE
- Для перевода в процентную или в «нормализованную» среднеквадратичную ошибку необходимо:
- Разделить на разницу между максимальным и минимальным значением показателей
- Разделить на разницу между третьим и первым квартилем значений показателей
- Разделить на среднее арифметическое значений показателей (наиболее часто встречающийся вариант)
MASE — Mean Absolute Scaled Error
MASE — средняя абсолютная масштабированная ошибка прогнозирования. Согласно Википедии, является очень хорошим вариантом для расчета точности, так как сама ошибка не зависит от масштабов данных и является симметричной: то есть положительные и отрицательные отклонения от факта рассматриваются в равной степени.
Важно! Если предыдущие ошибки прогнозирования мы могли использовать для нахождения точности прогнозирования некого списка номенклатур, где каждой из которых соответствует фактическое и прогнозное значение (как было в примере в начале статьи), то данная ошибка для этого не предназначена: MASE используется для расчета точности прогнозирования одной единственной позиции, основываясь на предыдущих показателях факта и прогноза, и чем больше этих показателей, тем более точно мы сможем рассчитать показатель точности. Вероятно, из-за этого ошибка не получила широкого распространения.
Здесь данная формула представлена исключительно для ознакомления и не рекомендуется к использованию.
Суть формулы заключается в нахождении среднего арифметического всех масштабированных ошибок, что при упрощении даст нам следующую конечную формулу:
Также, хочу отметить, что существует ошибка RMMSE (Root Mean Square Scaled Error — Среднеквадратичная масштабированная ошибка), которая примерно похожа на MASE, с теми же преимуществами и недостатками.
Это основные ошибки прогнозирования, которые могут использоваться для расчета точности прогнозирования. Но не все! Их очень много и, возможно, чуть позже я добавлю еще немного информации о некоторых из них. А примеры расчетов уже описанных ошибок прогнозирования будут выложены через некоторое время, пока что я подготавливаю пример, ожидайте.

