

Найти повторяющиеся значения в excel 2003
Поиск и удаление дубликатов в Excel: 5 методов
Большие таблицы Эксель могут содержать повторяющиеся данные, что зачастую увеличивает объем информации и может привести к ошибкам в результате обработки данных при помощи формул и прочих инструментов. Это особенно критично, например, при работе с денежными и прочими финансовыми данными.
В данной статье мы рассмотрим методы поиска и удаления дублирующихся данных (дубликатов), в частности, строк в Excel.
Метод 1: удаление дублирующихся строк вручную
Первый метод максимально прост и предполагает удаление дублированных строк при помощи специального инструмента на ленте вкладки “Данные”.
- Полностью выделяем все ячейки таблицы с данными, воспользовавшись, например, зажатой левой кнопкой мыши.
- Во вкладке “Данные” в разделе инструментов “Работа с данными” находим кнопку “Удалить дубликаты” и кликаем на нее.


- Переходим к настройкам параметров удаления дубликатов:
- Если обрабатываемая таблица содержит шапку, то проверяем пункт “Мои данные содержат заголовки” – он должен быть отмечен галочкой.
- Ниже, в основном окне, перечислены названия столбцов, по которым будет осуществляться поиск дубликатов. Система считает совпадением ситуацию, в которой в строках повторяются значения всех выбранных в настройке столбцов. Если убрать часть столбцов из сравнения, повышается вероятность увеличения количества похожих строк.
- Тщательно все проверяем и нажимаем ОК.

- Далее программа Эксель в автоматическом режиме найдет и удалит все дублированные строки.
- По окончании процедуры на экране появится соответствующее сообщение с информацией о количестве найденных и удаленных дубликатов, а также о количестве оставшихся уникальных строк. Для закрытия окна и завершения работы данной функции нажимаем кнопку OK.

Метод 2: удаление повторений при помощи “умной таблицы”
Еще один способ удаления повторяющихся строк – использование “умной таблицы“. Давайте рассмотрим алгоритм пошагово.
- Для начала, нам нужно выделить всю таблицу, как в первом шаге предыдущего раздела.

- Во вкладке “Главная” находим кнопку “Форматировать как таблицу” (раздел инструментов “Стили“). Кликаем на стрелку вниз справа от названия кнопки и выбираем понравившуюся цветовую схему таблицы.

- После выбора стиля откроется окно настроек, в котором указывается диапазон для создания “умной таблицы“. Так как ячейки были выделены заранее, то следует просто убедиться, что в окошке указаны верные данные. Если это не так, то вносим исправления, проверяем, чтобы пункт “Таблица с заголовками” был отмечен галочкой и нажимаем ОК. На этом процесс создания “умной таблицы” завершен.

- Далее приступаем к основной задаче – нахождению задвоенных строк в таблице. Для этого:
- ставим курсор на произвольную ячейку таблицы;
- переключаемся во вкладку “Конструктор” (если после создания “умной таблицы” переход не был осуществлен автоматически);
- в разделе “Инструменты” жмем кнопку “Удалить дубликаты“.
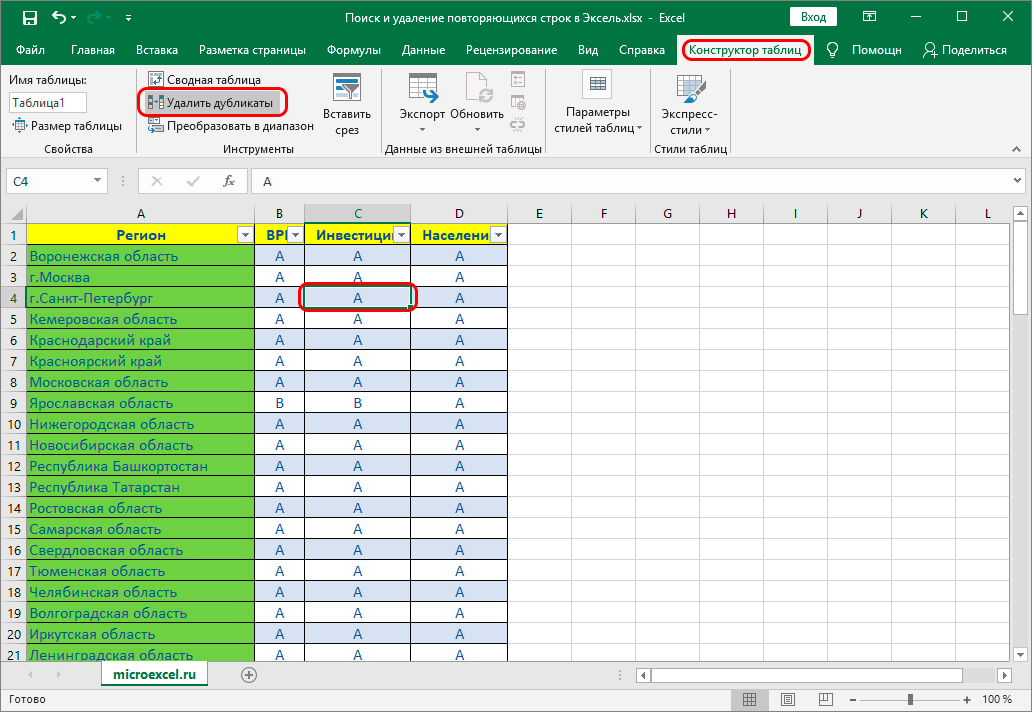
- Следующие шаги полностью совпадают с описанными в методе выше действиями по удалению дублированных строк.
Примечание: Из всех описываемых в данной статье методов этот является наиболее гибким и универсальным, позволяя комфортно работать с таблицами различной структуры и объема.
Метод 3: использование фильтра
Следующий метод не удаляет повторяющиеся строки физически, но позволяет настроить режим отображения таблицы таким образом, чтобы при просмотре они скрывались.
- Как обычно, выделяем все ячейки таблицы.
- Во вкладке “Данные” в разделе инструментов “Сортировка и фильтр” ищем кнопку “Фильтр” (иконка напоминает воронку) и кликаем на нее.

- После этого в строке с названиями столбцов таблицы появятся значки перевернутых треугольников (это значит, что фильтр включен). Чтобы перейти к расширенным настройкам, жмем кнопку “Дополнительно“, расположенную справа от кнопки “Фильтр“.

- В появившемся окне с расширенными настройками:
- как и в предыдущем способе, проверяем адрес диапазон ячеек таблицы;
- отмечаем галочкой пункт “Только уникальные записи“;
- жмем ОК.

- После этого все задвоенные данные перестанут отображаться в таблицей. Чтобы вернуться в стандартный режим, достаточно снова нажать на кнопку “Фильтр” во вкладке “Данные”.

Метод 4: условное форматирование
Условное форматирование – гибкий и мощный инструмент, используемый для решения широкого спектра задач в Excel. В этом примере мы будем использовать его для выбора задвоенных строк, после чего их можно удалить любым удобным способом.
- Выделяем все ячейки нашей таблицы.
- Во вкладке “Главная” кликаем по кнопке “Условное форматирование“, которая находится в разделе инструментов “Стили“.
- Откроется перечень, в котором выбираем группу “Правила выделения ячеек“, а внутри нее – пункт “Повторяющиеся значения“.

- Окно настроек форматирования оставляем без изменений. Единственный его параметр, который можно поменять в соответствии с собственными цветовыми предпочтениями – это используемая для заливки выделяемых строк цветовая схема. По готовности нажимаем кнопку ОК.

- Теперь все повторяющиеся ячейки в таблице “подсвечены”, и с ними можно работать – редактировать содержимое или удалить строки целиком любым удобным способом.
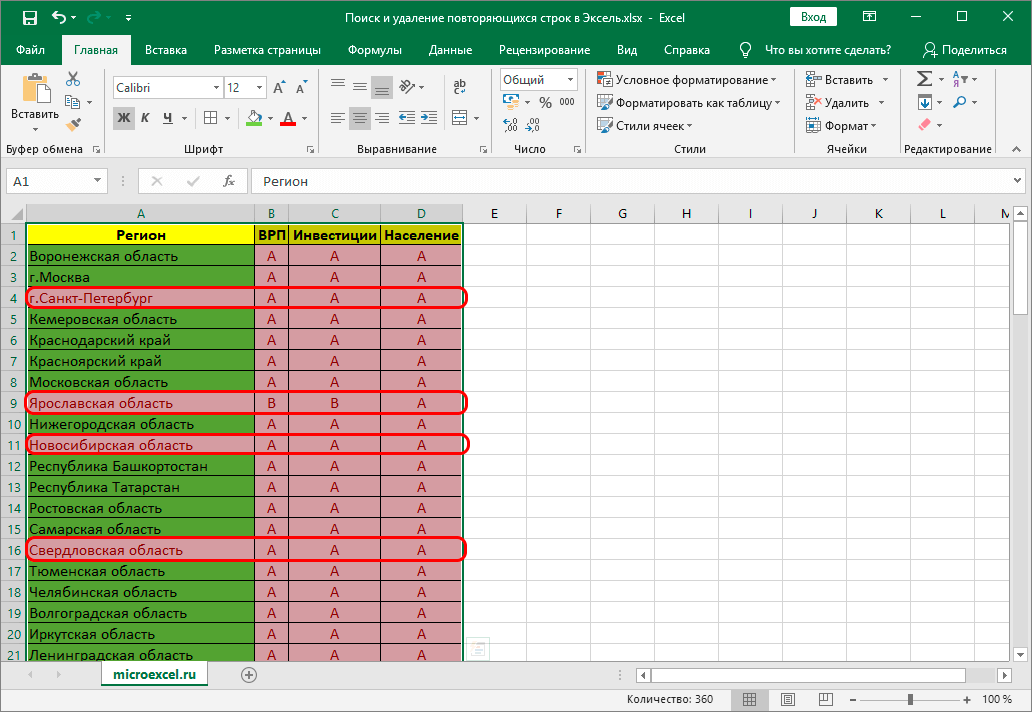
Важно! Этом метод не настолько универсален, как описанные выше, так как выделяет все ячейки с одинаковыми значениями, а не только те, для которых совпадает вся строка целиком. Это видно на предыдущем скриншоте, когда нужные задвоения по названиям регионов были выделены, но вместе с ними отмечены и все ячейки с категориями регионов, потому что значения этих категорий повторяются.
Метод 5: формула для удаления повторяющихся строк
Последний метод достаточно сложен, и им мало, кто пользуется, так как здесь предполагается использование сложной формулы, объединяющей в себе несколько простых функций. И чтобы настроить формулу для собственной таблицы с данными, нужен определенный опыт и навыки работы в Эксель.
Формула, позволяющая искать пересечения в пределах конкретного столбца в общем виде выглядит так:
Давайте посмотрим, как с ней работать на примере нашей таблицы:
- Добавляем в конце таблицы новый столбец, специально предназначенный для отображения повторяющихся значений (дубликаты).

- В верхнюю ячейку нового столбца (не считая шапки) вводим формулу, которая для данного конкретного примера будет иметь вид ниже, и жмем Enter:
=ЕСЛИОШИБКА(ИНДЕКС(A2:A90;ПОИСКПОЗ(0;СЧЁТЕСЛИ(E1:$E$1;A2:A90)+ЕСЛИ(СЧЁТЕСЛИ(A2:A90;A2:A90)>1;0;1);0));»») .
- Выделяем до конца новый столбец для задвоенных данных, шапку при этом не трогаем. Далее действуем строго по инструкции:
- ставим курсор в конец строки формул (нужно убедиться, что это, действительно, конец строки, так как в некоторых случаях длинная формула не помещается в пределах одной строки);
- жмем служебную клавишу F2 на клавиатуре;
- затем нажимаем сочетание клавиш Ctrl+SHIFT+Enter.
- Эти действия позволяют корректно заполнить формулой, содержащей ссылки на массивы, все ячейки столбца. Проверяем результат.

Как уже было сказано выше, этот метод сложен и функционально ограничен, так как не предполагает удаления найденных столбцов. Поэтому, при прочих равных условиях, рекомендуется использовать один из ранее описанных методов, более логически понятных и, зачастую, более эффективных.
Заключение
Excel предлагает несколько инструментов для нахождения и удаления строк или ячеек с одинаковыми данными. Каждый из описанных методов специфичен и имеет свои ограничения. К универсальным варианту мы, пожалуй, отнесем использование “умной таблицы” и функции “Удалить дубликаты”. В целом, для выполнения поставленной задачи необходимо руководствоваться как особенностями структуры таблицы, так и преследуемыми целями и видением конечного результата.
Ищем дубликаты значений в ячейках
Воспользуемся возможностями условного форматирования. Эту тему мы уже рассматривали в статье «Закрасить ячейку по условию или формуле», а теперь применим для решения другой задачи.
Ищем повторяющиеся записи в Excel 2007
Выделим столбец, в котором будем искать дубликаты (в нашем примере это столбец с каталожными номерами), и на главной вкладке ищем кнопку «Условное форматирование». Далее по пунктам, как на рисунке. 
В новом окне нам остается только согласиться с предлагаемым цветовым решением (или выбрать другое) и нажать «ОК». 
Теперь повторяющиеся значения у нас окрашены в красный цвет. Но они разбросаны по всей таблице и это неудобно. Нужно отсортировать строки, чтобы собрать их в кучку. Обратите внимание, что в приведенной таблице есть столбец «№ п/п», содержащий номера строк. Если у вас его нет, его следует сделать, чтобы мы потом смогли восстановить исходный порядок данных в таблице.
Выделяем всю таблицу, переходим на вкладку «Данные» и жмем на кнопку «Сортировка». В новом окне нам нужно задать порядок сортировки. Выставляем нужные нам значения и добавляем следующий уровень. Нам нужно отсортировать строки сначала по цвету ячеек, а потом по значению в ячейке, чтобы дубликаты оказались рядом друг с другом. 
Разбираемся с найденными дубликатами. В данном случае повторяющиеся строки можно просто удалить. 
Обратите внимание, что по мере удаления дубликатов красные ячейки возвращают себе белый цвет.
Избавившись от цветных ячеек, снова выделим всю таблицу и отсортируем ее по столбцу «№п/п». После этого останется только поправить сбившуюся из-за удаленных строк нумерацию.
Как это сделать в Excel 2003
Здесь будет немного сложнее – придется использовать логическую функцию «СЧЕТЕСЛИ()».
Войдите в ячейку с первым значением, среди которых вы будете искать дубликаты.
В первом поле выберите «Формула» и введите формулу «=СЧЕТЕСЛИ(C;RC)>1». Только не забудьте вовремя переключить раскладку – «СЧЕТЕСЛИ» набирается в русской раскладке, а «(C;RC)>1» в английской. 
Цвет выберите, нажав на кнопку «Формат» на закладке «Вид».
Теперь нам нужно скопировать этот формат на весь столбец.
Выделяем весь столбец с проверяемыми данными.

Выбираем «Форматы», «ОК» и условное форматирование скопировалось на весь столбец.
Покоряйте Excel и до новых встреч!
Комментарии:
- asd — 10.11.2015 13:37
Найти дубли в экселе +100500. Спасибо!! А я то голову ломал ))
Как удалить дубли в Excel 2003
 Кроха сын к отцу пришел, и спросила кроха…
Кроха сын к отцу пришел, и спросила кроха…
Нет, не так. На самом деле подошел сотрудник и сказал — а не поставить ли нам эксель 2010? По опыту знаю, что ему требуется пару раз в день заполнять небольшую таблицу, ничего архисложного. Поэтому сразу возник логичный вопрос — а тебе зачем? На что вполне логичный ответ — а там можно одной командой дублирующиеся ячейки удалить. Угу. То есть 3-4 т.р. за то, чтобы дубли удалить. А надо сказать, я вообще очень плохо отношусь к неоправданным расходам в бизнесе. Одно дело, когда что-то требуется для непосредственного выполнения какой-либо функции, которую ни в чем другом выполнить нельзя. Или занимает столько времени, что дешевле оптимизировать, или написать под это специальную программу — вот сейчас, например, пишем за полторы штуки баксов одну такую. А другое дело, когда кто-то хочет на 10 минут подольше посидеть во вконтакте в рабочее время, и просто ленится разобраться, как пару кнопок нажать.
Ну ладно, сейчас расскажу, как удалить дубликаты в excel 2003, и можно идти дальше придумывать, зачем еще 2010-й тебе может понадобиться (не, для чего он нужен мне — я прекрасно знаю :-)).
Самый простой способ а) — как удалить повторяющиеся значения excel:
1. Берем, выделяем диапазон ячеек с дублями, нажимаем на Данные -> Фильтр -> Расширенный фильтр…
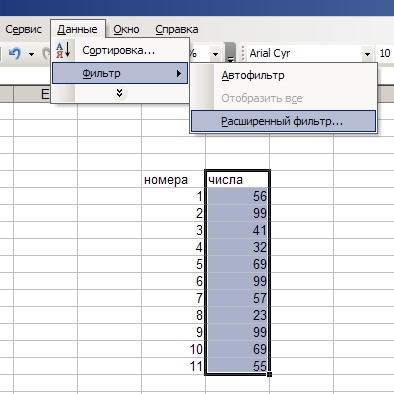
2. Дальше — в появившемся окошке отмечаем чек-бокс «Только уникальные записи», нажимаем ОК.
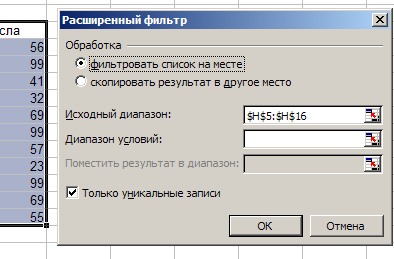
3. Получаем результат, который можно сделать Ctrl+C — Ctrl+V на нужное место/лист.
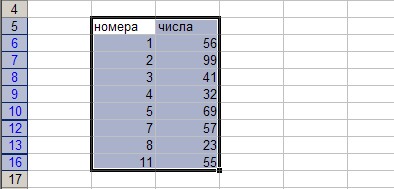
Теперь вариант B), для тех, кто не боится сложностей ?
1. Левее крайнего левого столбца нашей таблицы вставляем дополнительный столбец (допустим, у нас был А — вставим еще один А, чтобы наш стал B), и в нем проставляем порядковые номера (обычным вводом в ячейках цифр 1 и 2, выделяя эти две ячейки и двойным кликом на черной точке в правом нижнем углу все распространяется до конца диапазона). Это нам потребуется потом, если мы захотим восстановить порядок следования записей, если он не важен — так можно и не делать. Получится примерно так:
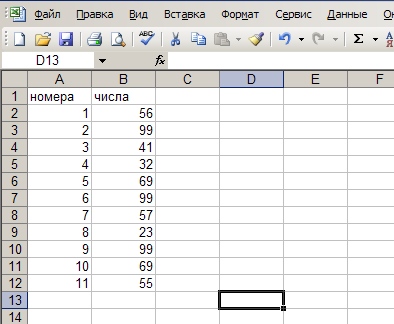
2. Дальше, выделяем две ячейки в строчке 2, с зажатым шифтом щелкаем на нижней границе выделения, таким образом — выделив все с A2 по B12. Жмем Данные ->Сортировка.

3. Сортируем список по столбцу B, скажем, по возрастанию.
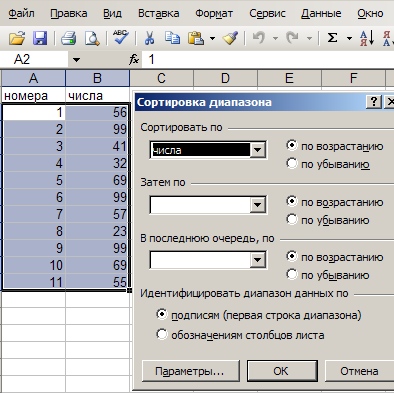
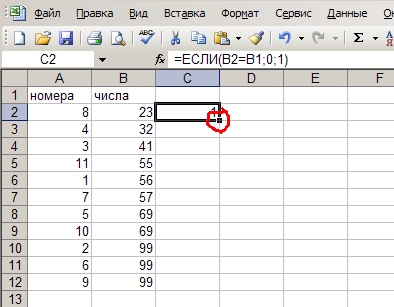
4. В ячейку C2 вставляем формулу =ЕСЛИ(B2=B1;0;1), которая сравнивает каждое значение с предыдущим. Если строка — дубль, то ей будет присвоено значение 0, если нет — то 1. Ну, конечно, значения B2 и B1 — это на моем примере, все зависит, сколько столбцов в таблице.
5. Щелкаем на обведенную красным кружочком точку в правом нижнем углу ячейки, чтобы продлить формулу на всю колонку (аналогично, как мы вставляли порядковые номера):
6. С полученным результатом делаем Ctrl+C, идем в Правка -> Специальная вставка
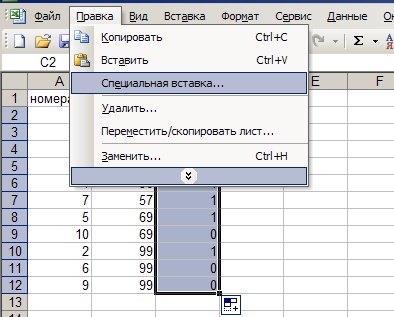
7. В открывшемся диалоге выбираем — Вставить Значения
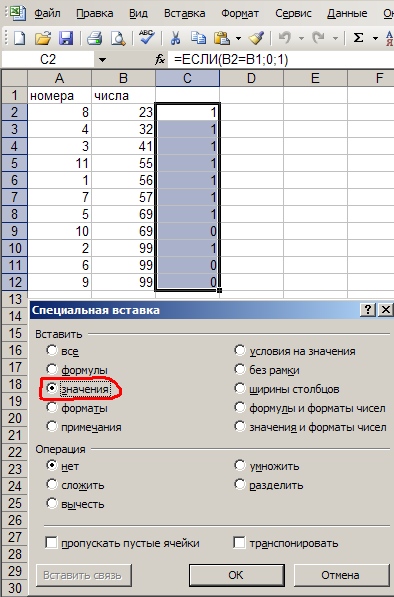
8. Теперь выделяем первые три ячейки в строке 2, с зажатым шифтом щелкаем на нижней границе выделения, таким образом — выделив все с A2 по С12. Жмем Данные ->Сортировка, сортируем по столбцу С, по убыванию (это важно — отсортировать именно по убыванию! Если бы мы дублям назначили 1, а не 0 — то надо было бы отсортировывать наоборот, по возрастанию). Скриншот приводить не буду, поскольку абсолютно аналогично шагам 2 и 3.
9. Выделяем столбец С, нажимаем Ctrl-F, вводим в форму поиска 0, и ищем в этом столбце первую по порядку ячейку с нулем.
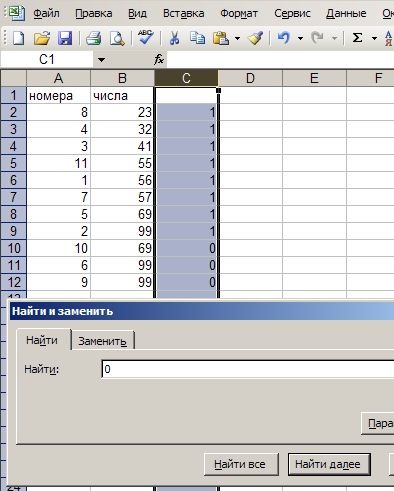
10. Выделяем всю строку, с А по С, в которой ноль впервые нашелся, с зажатым шифтом щелкаем мышкой на нижней границе выделения, таким образом — выделив все значения ниже. Далее делаем с ними все, что захотим: можем удалить к чертовой матери, а можем скопировать куда-либо эти дубли. Предположим, что удалили.
11. Удаляем значения из столбца С — он тоже свою роль сыграл.
12. Выделяем целиком столбцы А и B, жмем Данные ->Сортировка, и сортируем по столбцу А (в моем случае — по номерам) по возрастанию.
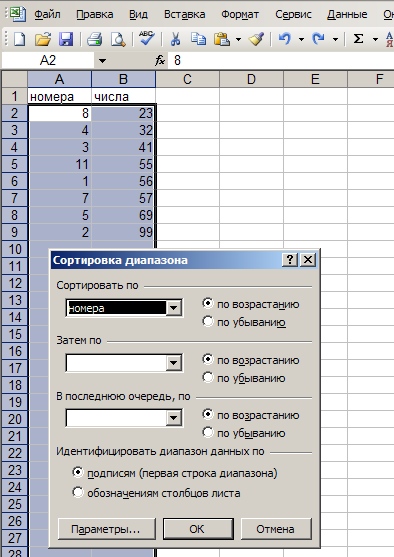
13. В получившемся списке удаляем колонку А, и получаем в результате таблицу, аналогичную исходной, но без дублей. Для сравнения в столбце D привел то, как она выглядела до всех этих итераций.
Описывать это все гораздо дольше, чем делать, в принципе — уходит максимум 30 секунд.
Как найти одинаковые значения в столбце Excel
Поиск дублей в Excel – это одна из самых распространенных задач для любого офисного сотрудника. Для ее решения существует несколько разных способов. Но как быстро как найти дубликаты в Excel и выделить их цветом? Для ответа на этот часто задаваемый вопрос рассмотрим конкретный пример.
Как найти повторяющиеся значения в Excel?
Допустим мы занимаемся регистрацией заказов, поступающих на фирму через факс и e-mail. Может сложиться такая ситуация, что один и тот же заказ поступил двумя каналами входящей информации. Если зарегистрировать дважды один и тот же заказ, могут возникнуть определенные проблемы для фирмы. Ниже рассмотрим решение средствами условного форматирования.
Чтобы избежать дублированных заказов, можно использовать условное форматирование, которое поможет быстро найти одинаковые значения в столбце Excel.
Пример дневного журнала заказов на товары:
Чтобы проверить содержит ли журнал заказов возможные дубликаты, будем анализировать по наименованиям клиентов – столбец B:
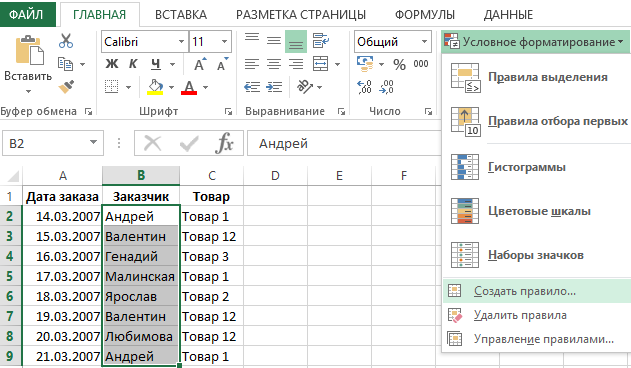
- Выделите диапазон B2:B9 и выберите инструмент: «ГЛАВНАЯ»-«Стили»-«Условное форматирование»-«Создать правило».
- Вберете «Использовать формулу для определения форматируемых ячеек».
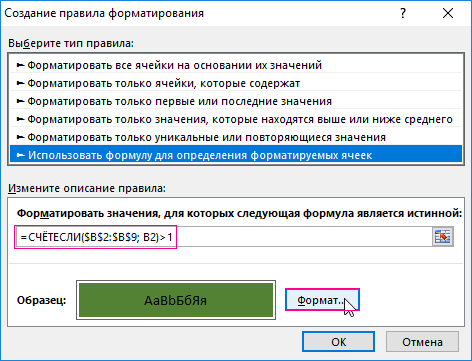
- Чтобы найти повторяющиеся значения в столбце Excel, в поле ввода введите формулу: =СЧЁТЕСЛИ($B$2:$B$9; B2)>1.
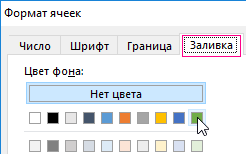
- Нажмите на кнопку «Формат» и выберите желаемую заливку ячеек, чтобы выделить дубликаты цветом. Например, зеленый. И нажмите ОК на всех открытых окнах.
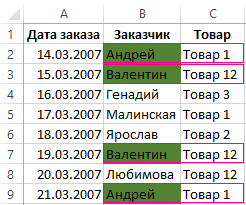
Как видно на рисунке с условным форматированием нам удалось легко и быстро реализовать поиск дубликатов в Excel и обнаружить повторяющиеся данные ячеек для таблицы журнала заказов.
Пример функции СЧЁТЕСЛИ и выделение повторяющихся значений
Принцип действия формулы для поиска дубликатов условным форматированием – прост. Формула содержит функцию =СЧЁТЕСЛИ(). Эту функцию так же можно использовать при поиске одинаковых значений в диапазоне ячеек. В функции первым аргументом указан просматриваемый диапазон данных. Во втором аргументе мы указываем что мы ищем. Первый аргумент у нас имеет абсолютные ссылки, так как он должен быть неизменным. А второй аргумент наоборот, должен меняться на адрес каждой ячейки просматриваемого диапазона, потому имеет относительную ссылку.
Самые быстрые и простые способы: найти дубликаты в ячейках.
После функции идет оператор сравнения количества найденных значений в диапазоне с числом 1. То есть если больше чем одно значение, значит формула возвращает значение ИСТЕНА и к текущей ячейке применяется условное форматирование.

