

Html to plain text
How do you convert Html to plain text?
I have snippets of Html stored in a table. Not entire pages, no tags or the like, just basic formatting.
I would like to be able to display that Html as text only, no formatting, on a given page (actually just the first 30 — 50 characters but that’s the easy bit).
How do I place the «text» within that Html into a string as straight text?
So this piece of code.
Hello World. Is there anyone out there?
19 Answers 19
If you are talking about tag stripping, it is relatively straight forward if you don’t have to worry about things like «, System.Text.RegularExpressions.RegexOptions.IgnoreCase); //result = System.Text.RegularExpressions.Regex.Replace(result, // @»()])*( )», // string.Empty, // System.Text.RegularExpressions.RegexOptions.IgnoreCase); result = System.Text.RegularExpressions.Regex.Replace(result, @»()»,string.Empty, System.Text.RegularExpressions.RegexOptions.IgnoreCase); // remove all styles (prepare first by clearing attributes) result = System.Text.RegularExpressions.Regex.Replace(result, @» ])*>»,»», System.Text.RegularExpressions.RegexOptions.IgnoreCase); result = System.Text.RegularExpressions.Regex.Replace(result, «()»,string.Empty, System.Text.RegularExpressions.RegexOptions.IgnoreCase); // insert tabs in spaces of
and
tags result = System.Text.RegularExpressions.Regex.Replace(result, @» «,»r», System.Text.RegularExpressions.RegexOptions.IgnoreCase); result = System.Text.RegularExpressions.Regex.Replace(result, @» «,»r», System.Text.RegularExpressions.RegexOptions.IgnoreCase); // insert line paragraphs (double line breaks) in place // if
and
Escape characters such as n and r had to be removed first because they cause regexes to cease working as expected.
Moreover, to make the result string display correctly in the textbox, one might need to split it up and set textbox’s Lines property instead of assigning to Text property.
Free online HTML code converter
Convert any document to clean HTML. This free online code formatter will help you compose your documents quickly and easily. You can preview and adjust the visual document and the source code side by side. Edit any of these fields and the changes will be reflected in the other one instantly as you’re typing.
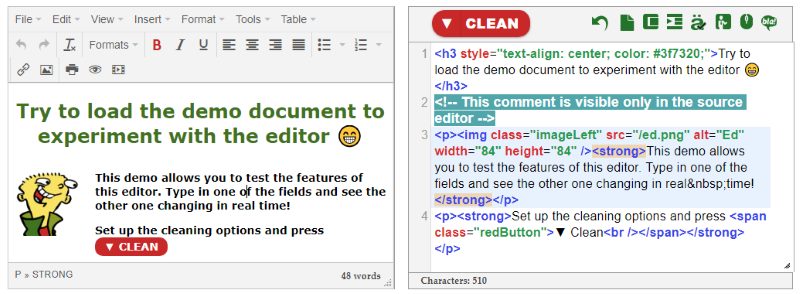
WYSIWYG «what you see is what you get» composer
The operation of this visual word composer is very intuitive. It behaves like Microsoft Word, Open office or any other rich text editor and it helps you preview how your elements will look when you publish your article on a website. Please note that the exact appearance might be different, according to the CSS file of the website.
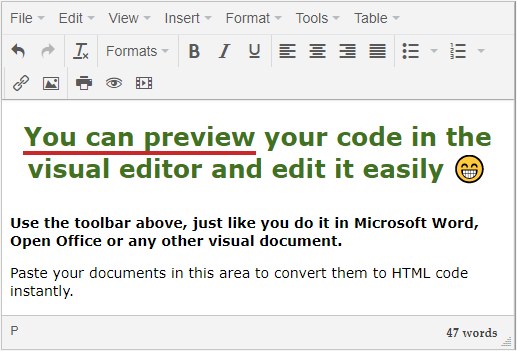
Work with the source code
Syntax highlighted HTML code reviser with many useful features, such as:
- Line number counter
- Active line highlighting
- Highlighted opening and matching closing tags
- Automatic tag closing
- see below for more.
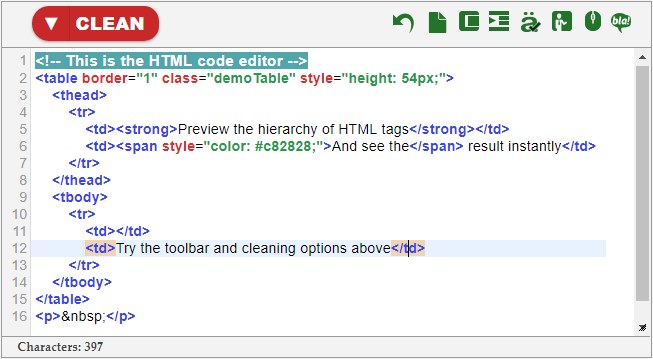
Cleaning options:

Open the dropdown в–ј menu to reveal the cleaning options. The checked options are executed once you press the main HTML cleaning button. Press the icon on the right to perform only one of them.
- Inline styles – Strip every style tag attribute. It’s recommended to use a separate CSS file for styling.
- > Empty tags – Erases tags that contain nothing or just a space.
- Tags with one space – Clears tags that contain a single space, such as
HTML Cleaning Source Code Editing Area
The list of source composer options is located next to the Clean button. These green icons allow you to execute the following features:

- Undo – Restore the document to the previous state. Go back to the previous stage if a cleaning option doesn’t give you the desired result.
- New page – Erase the whole document to start with a blank page.
- Compress – Tabs and new lines are used to make an HTML file more readable for humans but they don’t affect the rendering in the web browser. Remove these unnecessary characters to minimize the file size and provide a faster page loading speed.
- Tree view – Set text indentation to highlight the tag hierarchy. You can make compressed documents readable again with this option.
- Character encoding – Decide whether you’d like to encode special characters or not. For example
- Demo content – Populate the dashboard with a demo content that helps you experiment with this tool. The demo contains a heading, a table, an image, paragraphs and other elements.
- Scroll text areas together – By default the two fields scroll together when the document is large. You can disable this feature.
- Add gibberish text – Adds a paragraph of «Lorem ipsum» to the end of your file. Press it again to add a different one.
Terms & Conditions
The content of the pages of this website is for your general information and use only. It is subject to change without notice.
Neither we nor any third parties provide any warranty or guarantee as to the accuracy, timeliness, performance, completeness or suitability of the information and materials found or offered on this website for any particular purpose. You acknowledge that such information and materials may contain inaccuracies or errors and we expressly exclude liability for any such inaccuracies or errors to the fullest extent permitted by law.
Your use of any information or materials on this website is entirely at your own risk, for which we shall not be liable. It shall be your own responsibility to ensure that any products, services or information available through this website meet your specific requirements.
This website contains material which is owned by or licensed to us. This material includes, but is not limited to, the design, layout, look, appearance and graphics. Reproduction is prohibited other than in accordance with the copyright notice, which forms part of these terms and conditions.
All trademarks reproduced in this website, which are not the property of, or licensed to the operator, are acknowledged on the website.
Unauthorised use of this website may give rise to a claim for damages and/or be a criminal offence.
From time to time, this website may also include links to other websites. These links are provided for your convenience to provide further information. They do not signify that we endorse the website(s). We have no responsibility for the content of the linked website(s).
Privacy Policy
As stated in the sidebar on each pages, this tool is using cookies to improve the user experience and to collect anonymous visitor analytics. We use third parties that are also using cookies. Please check the source code or use a browser pluging to locate them.
HTMLed.it is not sending the documents to our server, the conversions and all operations are performed on the client side. The site is not connected to a database which means that we’re not storing any personal data about our visitors.
Click here to edit this text or paste your document here to convert it to HTML рџЃ
 This demo allows you to test the features of this HTML converter. Type in one of the fields and see the other one changing in real time!
This demo allows you to test the features of this HTML converter. Type in one of the fields and see the other one changing in real time!
Set up the cleaning options and press в–ј Clean
Work with any of the text areas and see the other one changing in real time:
| Left : Preview | Right : Source code |
| Preview how your document will look when published. | Adjust the syntax highlighted HTML code. |
Check out GeekPrank for nice online pranks.
Subscribe for a membership
- No ads
- No limitations
- More features
Subscribe
Share this with your friends
Please disable the ad blocker
This website is using cookies to improve the user experience and to collect anonymous visitor analytics.
Html to plain text


An advanced converter that parses HTML and returns beautiful text. It was mainly designed to transform HTML E-Mail templates to a text representation. So it is currently optimized for table layouts.
- Transform headlines to uppercase text.
- Convert tables to an appropiate text representation with rows and columns.
- Word wrapping for paragraphs (default 80 chars).
- Automatic extraction of href information from links.
- conversion to n .
- Unicode support.
- Runs in browser and server environments.
Or when you want to use it as command line interface it is recommended to install it globally via
You can configure the behaviour of html-to-text with the following options:
- tables allows to select certain tables by the class or id attribute from the HTML document. This is necessary because the majority of HTML E-Mails uses a table based layout. Prefix your table selectors with an . for the class and with a # for the id attribute. All other tables are ignored. You can assign true to this attribute to select all tables. Default: []
- wordwrap defines after how many chars a line break should follow in p elements. Set to null or false to disable word-wrapping. Default: 80
- linkHrefBaseUrl allows you to specify the server host for href attributes, where the links start at the root ( / ). For example, linkHrefBaseUrl = ‘http://asdf.com’ and . the link in the text will be http://asdf.com/dir/subdir . Keep in mind that linkHrefBaseUrl shouldn’t end with a / .
- hideLinkHrefIfSameAsText by default links are translated the following text => becomes => text [link] . If this option is set to true and link and text are the same, [link] will be hidden and only text visible.
- noLinkBrackets dont print brackets around the link if true .
- ignoreHref ignore all document links if true .
- ignoreImage ignore all document images if true .
- preserveNewlines by default, any newlines n in a block of text will be removed. If true , these newlines will not be removed.
- decodeOptions defines the text decoding options given to he.decode . For more informations see the he module.
- uppercaseHeadings by default, headings (
, etc) are uppercased. Set to false to leave headings as they are.
- wrapCharacters is an array containing the characters that may be wrapped on, these are used in order
- forceWrapOnLimit defines whether to break long words on the limit if true .
- . Default: ‘ * ‘
Override formatting for specific elements
By using the format option, you can specify formatting for these elements: text , image , lineBreak , paragraph , anchor , heading , table , orderedList , unorderedList , listItem , horizontalLine .
Each key must be a function which eventually receive elem (the current elem), fn (the next formatting function) and options (the options passed to html-to-text).
Command Line Interface
It is possible to use html-to-text as command line interface. This allows an easy validation of your generated text and the integration in other systems that does not run on node.js.
html-to-text uses stdin and stdout for data in and output. So you can use html-to-text the following way:
There also all options available as described above. You can use them like this:
The tables option has to be declared as comma separated list without whitespaces.
Gets converted to:
(The MIT License)
Copyright (c) 2019 werk85
Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the ‘Software’), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED ‘AS IS’, WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
Convert Plain Text to HTML
Many apps and software that let you type in text for publishing on web pages automatically convert what you type into HTML.
HTML tags p and br are the most common HTML tags inserted during the conversion. Some also create img tags from image URLs found in the plain text. And create clickable links from URLs.
There are, however, apps and software that require you to provide your own HTML markup.
It can be time consuming or even a challenge to take plain text and edit it to display in a browser with valid HTML.
This morning, while casting about for an article topic, I found out I’ve been remiss: No plain text to HTML converter was anywhere on the willmaster.com website.
Oh, there are a lot of converters, over two dozen as a matter of fact. See the generators and converters index page. But no plain text to HTML converter.
Today that is rectified. The plain text to HTML converter has been created. Use it in any of three locations.
The software can be used on this page (further below in this article) to convert your plain text into HTML. Paste or type in your text and click the button.
The form and conversion functionality can be installed on your web page with one line of JavaScript. It works on WordPress and on non-WordPress pages.
The PHP plain text to HTML conversion software can be downloaded and installed on your domain.
The Plain Text to HTML Converter
Here is the converter. Use it right here in this article.
The software currently inserts p and br HTML tags.
Click a button to convert plain text into valid HTML code.
Wherever one or more blank lines occur, the p tag is used. Hard returns without a blank line get br tags.
Updates planned for the near future include:
DONE (version 1.1)
Make img tags from absolute http://. image URLs — image URLs being defined as file names ending with .gif, .jpg, .jpeg, and .png.
DONE (version 1.1)
Make clickable links from absolute http://. non-image URLs.
Convert one-paragraph lists to ordered or unordered lists.
Provide choice of HTML or XHTML coding.
Provide choice where to put the
tag (beginning of line, ending of line, within line).
The updates will automatically be applied to
- the converter on this page and
- the converter you get when you install the form and conversion functionality on your web page with the single line of JavaScript.
The downloadable software will need to be re-downloaded and re-installed for updates.
Converter on Your Page With One Line of JavaScript
The form and conversion functionality can be installed on your web page with this line of JavaScript.
Paste the JavaScript into your page and you’re good to go. If you publish with WordPress, use the «Text» tab, not the «Visual» tab at your post/page editing interface.
It will work like the converter further above on this page because it’s pulled into the article by that same JavaScript. Depending on your CSS, the design on your page may be different.
Downloadable Plain Text to HTML Converter
The download is a complete web page.
The web page can be downloaded and saved to your hard drive or the source code can be copied from this box and pasted into your own file. No customization is required, but may be desired. Notes follow the source code.
As stated, the source code is a complete web page. The page may be re-designed.
If the functionality is to be moved to a different web page, notice the two functionalities are separated and marked in the web page source code:
Where the plain text is typed or pasted into the form:
This is the last section on the page. It’s beginning is marked with
Where the conversion result is published:
This section is immediately above the plain text input section. It’s beginning is marked with
Each of the sections uses a >box-style to style the text boxes. You’ll find the style in the downloadable page’s head area.
You now have three options for converting plain text to HTML. It can be done on this page, on your page with a line of JavaScript, or on your site with the conversion software installed.
If you elect to download and install the software, check back occasionally to see if new conversion features have been added. The functionality inserted into your page with a line of JavaScript is automatically updated.
(This article first appeared in Possibilities ezine.)
Was this article helpful to you?
(anonymous form)

